9 Survival Analysis for Modeling Singular Events Over Time
In previous chapters, the outcomes we have been modeling have or have not occurred at a particular point in time following when the input variables were measured. For example, in Chapter 4 input variables were measured in the first three years of an education program and the outcome was measured at the end of the fourth year. In many situations, the outcome we are interested in is a singular event that can occur at any time following when the input variables were measured, can occur at a different time for different individuals, and once it has occurred it cannot reoccur or repeat. In medical studies, death can occur or the onset of a disease can be diagnosed at any time during the study period. In employment contexts, an attrition event can occur at various times throughout the year.
An obvious and simple way to deal with this would be to simply agree to look at a specific point in time and measure whether or not the event had occurred at that point, for example, ‘How many employees had left at the three-year point?’. Such an approach allows us to use standard generic regression models like those studied in previous chapters. But this approach has limitations.
Firstly, we are only able to infer conclusions about the likelihood of the event having occurred as at the end of the period of study. We cannot make inferences about the likelihood of the event throughout the period of study. Being able to say that attrition is twice as likely for certain types of individuals at any time throughout the three years is more powerful than merely saying that attrition is twice as likely at the three-year point.
Secondly, our sample size is constrained by the state of our data at the end of the period of study. Therefore if we lose track of an individual after two years and six months, that observation needs to be dropped from our data set if we are focused only on the three-year point. Wherever possible, loss of data is something a statistician will want to avoid as it affects the accuracy and statistical power of inferences, and also means research effort was wasted.
Survival analysis is a general term for the modeling of a time-associated binary non-repeated outcome, usually involving an understanding of the comparative risk of that outcome between two or more different groups of interest. There are two common components in an elementary survival analysis, as follows:
- A graphical representation of the future outcome risk of the different groups over time, using survival curves based on Kaplan-Meier estimates of survival rate. This is usually an effective way to establish prima facie relevance of a certain input variable to the survival outcome and is a very effective visual way of communicating the relevance of the input variable to non-statisticians.
- A Cox proportional hazard regression model to establish statistical significance of input variables and to estimate the effect of each input variable on the comparative risk of the outcome throughout the study period.
Those seeking a more in depth treatment of survival analysis should consult texts on its use in medical/clinical contexts, and a recommended source is Collett (2015). In this chapter we will use a walkthrough example to illustrate a typical use of survival analysis in a people analytics context.
The job_retention data set shows the results of a study of around 3,800 individuals employed in various fields of employment over a one-year period. At the beginning of the study, the individuals were asked to rate their sentiment towards their job. These individuals were then followed up monthly for a year to determine if they were still working in the same job or had left their job for a substantially different job. If an individual was not successfully followed up in a given month, they were no longer followed up for the remainder of the study period.
# if needed, get job_retention data
url <- "http://peopleanalytics-regression-book.org/data/job_retention.csv"
job_retention <- read.csv(url)
head(job_retention)## gender field level sentiment intention left month
## 1 M Public/Government High 3 8 1 1
## 2 F Finance Low 8 4 0 12
## 3 M Education and Training Medium 7 7 1 5
## 4 M Finance Low 8 4 0 12
## 5 M Finance High 7 6 1 1
## 6 F Health Medium 6 10 1 2For this walkthrough example, the particular fields we are interested in are:
-
gender: The gender of the individual studied -
field: The field of employment that they worked in at the beginning of the study -
level: The level of the position in their organization at the beginning of the study—Low,MediumorHigh -
sentiment: The sentiment score reported on a scale of 1 to 10 at the beginning of the study, with 1 indicating extremely negative sentiment and 10 indicating extremely positive sentiment -
left: A binary variable indicating whether or not the individual had left their job as at the last follow-up -
month: The month of the last follow-up
9.1 Tracking and illustrating survival rates over the study period
In our example, we are defining ‘survival’ as ‘remaining in substantially the same job’. We can regard the starting point as month 0, and we are following up in each of months 1 through 12. For a given month \(i\), we can define a survival rate \(S_i\) as follows
\[ S_i = S_{i - 1}(1 - \frac{l_i}{n_i}) \] where \(l_i\) is the number reported as left in month \(i\), and \(n_i\) is the number still in substantially the same job after month \(i - 1\), with \(S_0 = 1\).
The survival package in R allows easy construction of survival rates on data in a similar format to that in our job_retention data set. A survival object is created using the Surv() function to track the survival rate at each time period.
library(survival)
# create survival object with event as 'left' and time as 'month'
retention <- Surv(event = job_retention$left,
time = job_retention$month)
# view unique values of retention
unique(retention)## [1] 1 12+ 5 2 3 6 8 4 8+ 4+ 11 10 9 7+ 5+ 3+ 7 9+ 11+ 12 10+ 6+ 2+ 1+We can see that our survival object records the month at which the individual had left their job if they are recorded as having done so in the data set. If not, the object records the last month at which there was a record of the individual, appended with a ‘+’ to indicate that this was the last record available.
The survfit() function allows us to calculate Kaplan-Meier estimates of survival for different groups in the data so that we can compare them. We can do this using our usual formula notation but using a survival object as the outcome. Let’s take a look at survival by gender.
# kaplan-meier estimates of survival by gender
kmestimate_gender <- survival::survfit(
formula = Surv(event = left, time = month) ~ gender,
data = job_retention
)
summary(kmestimate_gender)## Call: survfit(formula = Surv(event = left, time = month) ~ gender,
## data = job_retention)
##
## gender=F
## time n.risk n.event survival std.err lower 95% CI upper 95% CI
## 1 1167 7 0.994 0.00226 0.990 0.998
## 2 1140 24 0.973 0.00477 0.964 0.982
## 3 1102 45 0.933 0.00739 0.919 0.948
## 4 1044 45 0.893 0.00919 0.875 0.911
## 5 987 30 0.866 0.01016 0.846 0.886
## 6 940 51 0.819 0.01154 0.797 0.842
## 7 882 43 0.779 0.01248 0.755 0.804
## 8 830 47 0.735 0.01333 0.709 0.762
## 9 770 40 0.697 0.01394 0.670 0.725
## 10 718 21 0.676 0.01422 0.649 0.705
## 11 687 57 0.620 0.01486 0.592 0.650
## 12 621 17 0.603 0.01501 0.575 0.633
##
## gender=M
## time n.risk n.event survival std.err lower 95% CI upper 95% CI
## 1 2603 17 0.993 0.00158 0.990 0.997
## 2 2559 66 0.968 0.00347 0.961 0.975
## 3 2473 100 0.929 0.00508 0.919 0.939
## 4 2360 86 0.895 0.00607 0.883 0.907
## 5 2253 56 0.873 0.00660 0.860 0.886
## 6 2171 120 0.824 0.00756 0.810 0.839
## 7 2029 85 0.790 0.00812 0.774 0.806
## 8 1916 114 0.743 0.00875 0.726 0.760
## 9 1782 96 0.703 0.00918 0.685 0.721
## 10 1661 50 0.682 0.00938 0.664 0.700
## 11 1590 101 0.638 0.00972 0.620 0.658
## 12 1460 36 0.623 0.00983 0.604 0.642We can see that the n.risk, n.event and survival columns for each group correspond to the \(n_i\), \(l_i\) and \(S_i\) in our formula above and that the confidence intervals for each survival rate are given. This can be very useful if we wish to illustrate a likely effect of a given input variable on survival likelihood.
Let’s imagine that we wish to determine if the sentiment of the individual had an impact on survival likelihood. We can divide our population into two (or more) groups based on their sentiment and compare their survival rates.
# create a new field to define high sentiment (>= 7)
job_retention$sentiment_category <- ifelse(
job_retention$sentiment >= 7,
"High",
"Not High"
)
# generate survival rates by sentiment category
kmestimate_sentimentcat <- survival::survfit(
formula = Surv(event = left, time = month) ~ sentiment_category,
data = job_retention
)
summary(kmestimate_sentimentcat)## Call: survfit(formula = Surv(event = left, time = month) ~ sentiment_category,
## data = job_retention)
##
## sentiment_category=High
## time n.risk n.event survival std.err lower 95% CI upper 95% CI
## 1 3225 15 0.995 0.00120 0.993 0.998
## 2 3167 62 0.976 0.00272 0.971 0.981
## 3 3075 120 0.938 0.00429 0.929 0.946
## 4 2932 102 0.905 0.00522 0.895 0.915
## 5 2802 65 0.884 0.00571 0.873 0.895
## 6 2700 144 0.837 0.00662 0.824 0.850
## 7 2532 110 0.801 0.00718 0.787 0.815
## 8 2389 140 0.754 0.00778 0.739 0.769
## 9 2222 112 0.716 0.00818 0.700 0.732
## 10 2077 56 0.696 0.00835 0.680 0.713
## 11 1994 134 0.650 0.00871 0.633 0.667
## 12 1827 45 0.634 0.00882 0.617 0.651
##
## sentiment_category=Not High
## time n.risk n.event survival std.err lower 95% CI upper 95% CI
## 1 545 9 0.983 0.00546 0.973 0.994
## 2 532 28 0.932 0.01084 0.911 0.953
## 3 500 25 0.885 0.01373 0.859 0.912
## 4 472 29 0.831 0.01618 0.800 0.863
## 5 438 21 0.791 0.01758 0.757 0.826
## 6 411 27 0.739 0.01906 0.703 0.777
## 7 379 18 0.704 0.01987 0.666 0.744
## 8 357 21 0.662 0.02065 0.623 0.704
## 9 330 24 0.614 0.02136 0.574 0.658
## 10 302 15 0.584 0.02171 0.543 0.628
## 11 283 24 0.534 0.02209 0.493 0.579
## 12 254 8 0.517 0.02218 0.476 0.563We can see that survival seems to consistently trend higher for those with high sentiment towards their jobs. The ggsurvplot() function in the survminer package can visualize this neatly and also provide additional statistical information on the differences between the groups, as shown in Figure 9.1.
library(survminer)
# show survival curves with p-value estimate and confidence intervals
survminer::ggsurvplot(
kmestimate_sentimentcat,
pval = TRUE,
conf.int = TRUE,
palette = c("blue", "red"),
linetype = c("solid", "dashed"),
xlab = "Month",
ylab = "Retention Rate"
)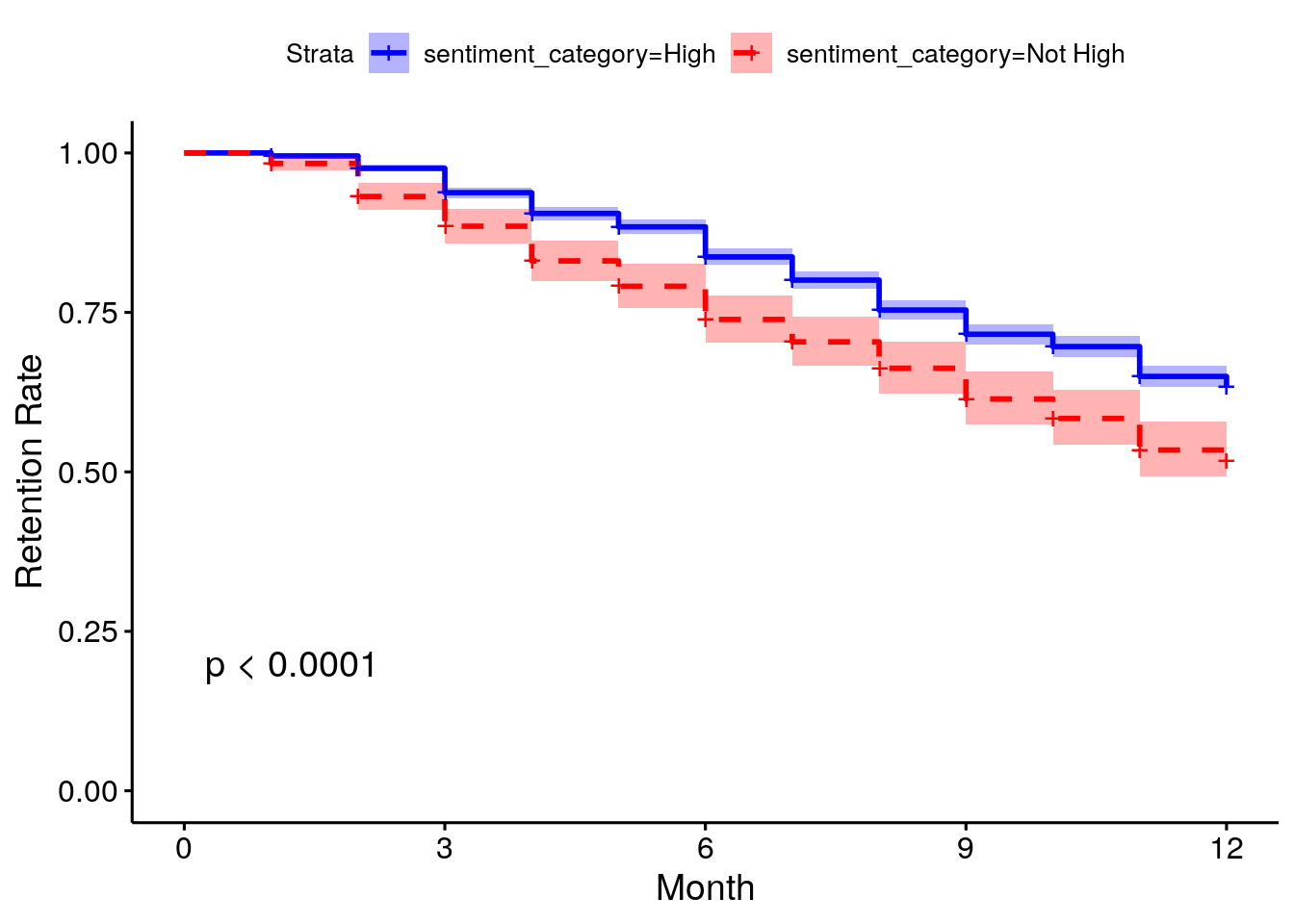
Figure 9.1: Survival curves by sentiment category in the job_retention data
This confirms that the survival difference between the two sentiment groups is statistically significant and provides a highly intuitive visualization of the effect of sentiment on retention throughout the period of study.
9.2 Cox proportional hazard regression models
Let’s imagine that we have a survival outcome that we are modeling for a population over a time \(t\), and we are interested in how a set of input variables \(x_1, x_2, \dots, x_p\) influences that survival outcome. Given that our survival outcome is a binary variable, we can model survival at any time \(t\) as a binary logistic regression. We define \(h(t)\) as the proportion who have not survived at time \(t\), called the hazard function, and based on our work in Chapter 5:
\[ h(t) = h_0(t)e^{\beta_1x_1 + \beta_2x_2 + \dots + \beta_px_p} \] where \(h_0(t)\) is a base or intercept hazard at time \(t\), and \(\beta_i\) is the coefficient associated with \(x_i\) .
Now let’s imagine we are comparing the hazard for two different individuals \(A\) and \(B\) from our population. We make an assumption that our hazard curves \(h^A(t)\) for individual \(A\) and \(h^B(t)\) for individual \(B\) are always proportional to each other and never cross—this is called the proportional hazard assumption. Under this assumption, we can conclude that
\[ \begin{aligned} \frac{h^B(t)}{h^A(t)} &= \frac{h_0(t)e^{\beta_1x_1^B + \beta_2x_2^B + \dots + \beta_px_p^B}}{h_0(t)e^{\beta_1x_1^A + \beta_2x_2^A + \dots + \beta_px_p^A}} \\ &= e^{\beta_1(x_1^B-x_1^A) + \beta_2(x_2^B-x_2^A) + \dots \beta_p(x_p^B-x_p^A)} \end{aligned} \]
Note that there is no \(t\) in our final equation. The important observation here is that the hazard for person B relative to person A is constant and independent of time. This allows us to take a complicating factor out of our model. It means we can model the effect of input variables on the hazard without needing to account for changes over times, making this model very similar in interpretation to a standard binomial regression model.
9.2.1 Running a Cox proportional hazard regression model
A Cox proportional hazard model can be run using the coxph() function in the survival package, with the outcome as a survival object. Let’s model our survival against the input variables gender, field, level and sentiment.
# run cox model against survival outcome
cox_model <- survival::coxph(
formula = Surv(event = left, time = month) ~ gender +
field + level + sentiment,
data = job_retention
)
summary(cox_model)## Call:
## survival::coxph(formula = Surv(event = left, time = month) ~
## gender + field + level + sentiment, data = job_retention)
##
## n= 3770, number of events= 1354
##
## coef exp(coef) se(coef) z Pr(>|z|)
## genderM -0.04548 0.95553 0.05886 -0.773 0.439647
## fieldFinance 0.22334 1.25025 0.06681 3.343 0.000829 ***
## fieldHealth 0.27830 1.32089 0.12890 2.159 0.030849 *
## fieldLaw 0.10532 1.11107 0.14515 0.726 0.468086
## fieldPublic/Government 0.11499 1.12186 0.08899 1.292 0.196277
## fieldSales/Marketing 0.08776 1.09173 0.10211 0.859 0.390082
## levelLow 0.14813 1.15967 0.09000 1.646 0.099799 .
## levelMedium 0.17666 1.19323 0.10203 1.732 0.083362 .
## sentiment -0.11756 0.88909 0.01397 -8.415 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## exp(coef) exp(-coef) lower .95 upper .95
## genderM 0.9555 1.0465 0.8514 1.0724
## fieldFinance 1.2502 0.7998 1.0968 1.4252
## fieldHealth 1.3209 0.7571 1.0260 1.7005
## fieldLaw 1.1111 0.9000 0.8360 1.4767
## fieldPublic/Government 1.1219 0.8914 0.9423 1.3356
## fieldSales/Marketing 1.0917 0.9160 0.8937 1.3336
## levelLow 1.1597 0.8623 0.9721 1.3834
## levelMedium 1.1932 0.8381 0.9770 1.4574
## sentiment 0.8891 1.1248 0.8651 0.9138
##
## Concordance= 0.578 (se = 0.008 )
## Likelihood ratio test= 89.18 on 9 df, p=2e-15
## Wald test = 94.95 on 9 df, p=<2e-16
## Score (logrank) test = 95.31 on 9 df, p=<2e-16The model returns the following40
Coefficients for each input variable and their p-values. Here we can conclude that working in Finance or Health is associated with a significantly greater likelihood of leaving over the period studied, and that higher sentiment is associated with a significantly lower likelihood of leaving.
Relative odds ratios associated with each input variable. For example, a single extra point in sentiment reduces the odds of leaving by ~11%. A single less point increases the odds of leaving by ~12%. Confidence intervals for the coefficients are also provided.
Three statistical tests on the null hypothesis that the coefficients are zero. This null hypothesis is rejected by all three tests which can be interpreted as meaning that the model is significant.
Importantly, as well as statistically validating that sentiment has a significant effect on retention, our Cox model has allowed us to control for possible mediating variables. We can now say that sentiment has a significant effect on retention even for individuals of the same gender, in the same field and at the same level.
9.2.2 Checking the proportional hazard assumption
Note that we mentioned in the previous section a critical assumption for our Cox proportional hazard model to be valid, called the proportional hazard assumption. As always, it is important to check this assumption before finalizing any inferences or conclusions from your model.
The most popular test of this assumption uses a residual known as a Schoenfeld residual, which would be expected to be independent of time if the proportional hazard assumption holds. The cox.zph() function in the survival package runs a statistical test on the null hypothesis that the Schoenfeld residuals are independent of time. The test is conducted on every input variable and on the model as a whole, and a significant result would reject the proportional hazard assumption.
(ph_check <- survival::cox.zph(cox_model))## chisq df p
## gender 0.726 1 0.39
## field 6.656 5 0.25
## level 2.135 2 0.34
## sentiment 1.828 1 0.18
## GLOBAL 11.156 9 0.27In our case, we can confirm that the proportional hazard assumption is not rejected. The ggcoxzph() function in the survminer package takes the result of the cox.zph() check and allows a graphical check by plotting the residuals against time, as seen in Figure 9.2.
survminer::ggcoxzph(ph_check,
font.main = 10,
font.x = 10,
font.y = 10)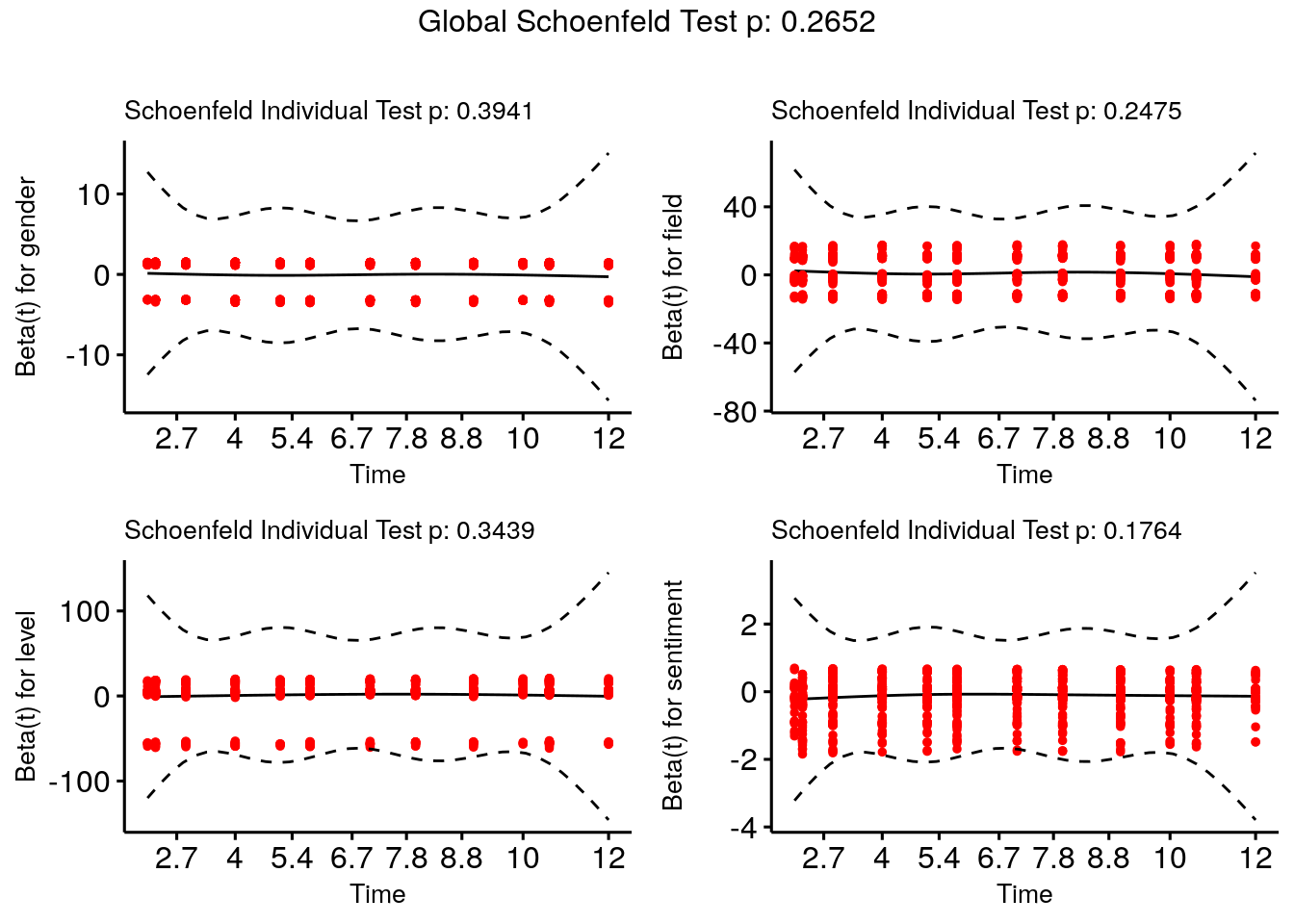
Figure 9.2: Schoenfeld test on proportional hazard assumption for cox_model
9.3 Frailty models
We noticed in our example in the previous section that certain fields of employment appeared to have a significant effect on the attrition hazard. It is therefore possible that different fields of employment have different base hazard functions, and we may wish to take this into account in determining if input variables have a significant relationship with attrition. This is analogous to a mixed model which we looked at in Section 8.1.
In this case we would apply a random intercept effect to the base hazard function \(h_0(t)\) according to the field of employment of an individual, in order to take this into account in our modeling. This kind of model is called a frailty model, taken from the clinical context, where different groups of patients may have different frailties (background risks of death).
There are many variants of how frailty models are run in the clinical context (see Collett (2015) for an excellent exposition of these), but the main application of a frailty model in people analytics would be to adapt a Cox proportional hazard model to take into account different background risks of the hazard event occurring among different groups in the data. This is called a shared frailty model. The frailtypack R package allows various frailty models to be run with relative ease. This is how we would run a shared frailty model on our job_retention data to take account of the different background attrition risk for the different fields of employment.
library(frailtypack)
(frailty_model <- frailtypack::frailtyPenal(
formula = Surv(event = left, time = month) ~ gender +
level + sentiment + cluster(field),
data = job_retention,
n.knots = 12,
kappa = 10000
))##
## Be patient. The program is computing ...
## The program took 1.04 seconds## Call:
## frailtypack::frailtyPenal(formula = Surv(event = left, time = month) ~
## gender + level + sentiment + cluster(field), data = job_retention,
## n.knots = 12, kappa = 10000)
##
##
## Shared Gamma Frailty model parameter estimates
## using a Penalized Likelihood on the hazard function
##
## coef exp(coef) SE coef (H) SE coef (HIH) z p
## genderM -0.0295295 0.970902 0.0593400 0.0593400 -0.497632 6.1874e-01
## levelLow 0.1985599 1.219645 0.0927706 0.0927706 2.140332 3.2328e-02
## levelMedium 0.2232823 1.250174 0.1043782 0.1043782 2.139166 3.2422e-02
## sentiment -0.1082618 0.897393 0.0143427 0.0143427 -7.548237 4.4076e-14
##
## chisq df global p
## level 5.17425 2 0.0752
##
## Frailty parameter, Theta: 48.3192 (SE (H): 33.2451 ) p = 0.073053
##
## penalized marginal log-likelihood = -5510.36
## Convergence criteria:
## parameters = 6.55e-05 likelihood = 9.89e-06 gradient = 6.43e-09
##
## LCV = the approximate likelihood cross-validation criterion
## in the semi parametrical case = 1.46587
##
## n= 3770
## n events= 1354 n groups= 6
## number of iterations: 18
##
## Exact number of knots used: 12
## Value of the smoothing parameter: 10000, DoF: 6.31We can see that the frailty parameter is significant, indicating that there is sufficient difference in the background attrition risk to justify the application of a random hazard effect. We also see that the level of employment now becomes more significant in addition to sentiment, with Low and Medium level employees more likely to leave compared to High level employees.
The frailtyPenal() function can also be a useful way to observe the different baseline survivals for groups in the data. For example, a simple stratified Cox proportional hazard model based on sentiment category can be constructed41.
stratified_base <- frailtypack::frailtyPenal(
formula = Surv(event = left, time = month) ~
strata(sentiment_category),
data = job_retention,
n.knots = 12,
kappa = rep(10000, 2)
)This can then be plotted to observe how baseline retention differs by group, as in Figure 9.342.
plot(stratified_base, type.plot = "Survival",
pos.legend = "topright", Xlab = "Month",
Ylab = "Baseline retention rate",
color = 1)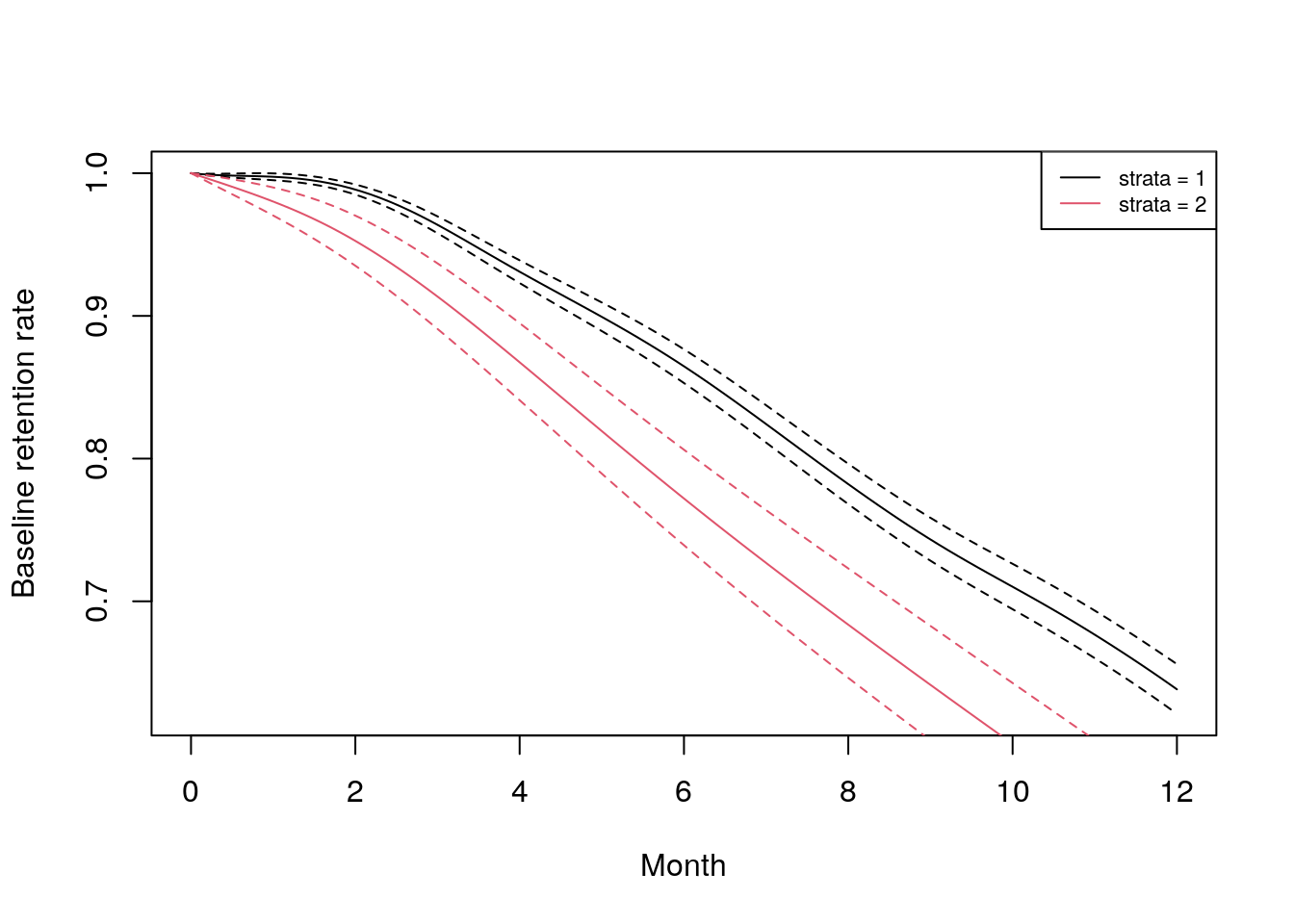
Figure 9.3: Baseline retention curves for the two sentiment categories in the job_retention data set
9.4 Learning exercises
9.4.1 Discussion questions
- Describe some of the reasons why a survival analysis is a useful tool for analyzing data where outcome events happen at different times.
- Describe the Kaplan-Meier survival estimate and how it is calculated.
- What are some common uses for survival curves in practice?
- Why is it important to run a Cox proportional hazard model in addition to calculating survival estimates when trying to understand the effect of a given variable on survival?
- Describe the assumption that underlies a Cox proportional hazard model and how this assumption can be checked.
- What is a frailty model, and why might it be useful in the context of survival analysis?
9.4.2 Data exercises
For these exercises, use the same job_retention data set as in the walkthrough example for this chapter, which can be loaded via the peopleanalyticsdata package or downloaded from the internet43. The intention field represents a score of 1 to 10 on the individual’s intention to leave their job in the next 12 months, where 1 indicates an extremely low intention and 10 indicates an extremely high intention. This response was recorded at the beginning of the study period.
- Create three categories of
intentionas follows: High (score of 7 or higher), Moderate (score of 4–6), Low (score of 3 or less) - Calculate Kaplan-Meier survival estimates for the three categories and visualize these using survival curves.
- Determine the effect of
intentionon retention using a Cox proportional hazard model, controlling forgender,fieldandlevel. - Perform an appropriate check that the proportional hazard assumption holds for your model.
- Run a similar model, but this time include the
sentimentinput variable. How would you interpret the results? - Experiment with running a frailty model to take into account the different background attrition risk by field of employment.