4 Linear Regression for Continuous Outcomes
In this chapter, we will introduce and explore linear regression, one of the first learning methods to be developed by statisticians and one of the easiest to interpret. Despite its simplicity—indeed because of its simplicity—it can be a very powerful tool in many situations. Linear regression will often be the first methodology to be trialed on a given problem, and will give an immediate benchmark with which to judge the efficacy of other, more complex, modeling techniques. Given the ease of interpretation, many analysts will select a linear regression model over more complex approaches even if those approaches produce a slightly better fit. This chapter will also introduce many critical concepts that will apply to other modeling approaches as we proceed through this book. Therefore for inexperienced modelers this should be considered a foundational chapter which should not be skipped.
4.1 When to use it
4.1.1 Origins and intuition of linear regression
Linear regression, also known as Ordinary Least Squares linear regression or OLS regression for short, was developed independently by the mathematicians Gauss and Legendre at or around the first decade of the 19th century, and there remains today some controversy about who should take credit for its discovery. However, at the time of its discovery it was not actually known as ‘regression’. This term became more popular following the work of Francis Galton—a British intellectual jack-of-all-trades and a cousin of Charles Darwin. In the late 1800s, Galton had researched the relationship between the heights of a population of almost 1000 children and the average height of their parents (mid-parent height). He was surprised to discover that there was not a perfect relationship between the height of a child and the average height of its parents, and that in general children’s heights were more likely to be in a range that was closer to the mean for the total population. He described this statistical phenomenon as a ‘regression towards mediocrity’ (‘regression’ comes from a Latin term approximately meaning ‘go back’).
Figure 4.1 is a scatter plot of Galton’s data with the black solid line showing what a perfect relationship would look like, the black dot-dashed line indicating the mean child height and the red dashed line showing the actual relationship determined by Galton16. You can regard the red dashed line as ‘going back’ from the perfect relationship (symbolized by the black line). This might give you an intuition that will help you understand later sections of this chapter. In an arbitrary data set, the red dashed line can lie anywhere between the black dot-dashed line (no relationship) and the black solid line (a perfect relationship). Linear regression is about finding the red dashed line in your data and using it to explain the degree to which your input data (the \(x\) axis) explains your outcome data (the \(y\) axis).
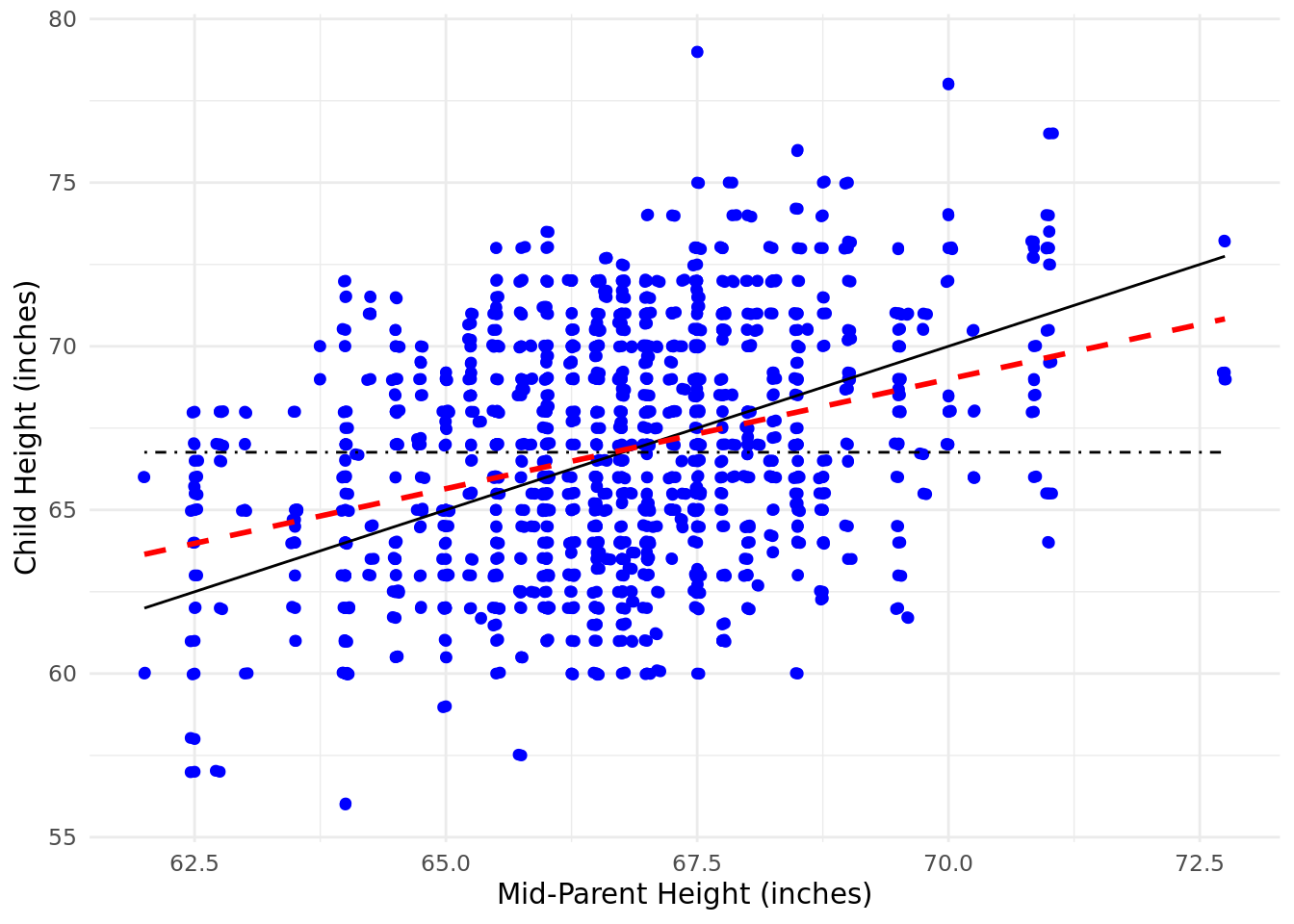
Figure 4.1: Galton’s study of the height of children introduced the term ‘regression’
4.1.2 Use cases for linear regression
Linear regression is particularly suited to a problem where the outcome of interest is on some sort of continuous scale (for example, quantity, money, height, weight). For outcomes of this type, it can be a first port of call before trying more complex modeling approaches. It is simple and easy to explain, and analysts will often accept a somewhat poorer fit using linear regression in order to avoid having to interpret a more complex model.
Here are some illustratory examples of questions that could be tackled with a linear regression approach:
Given a data set of demographic data, job data and current salary data, to what extent can current salary be explained by the rest of the data?
Given annual test scores for a set of students over a four-year period, what is the relationship between the final test score and earlier test scores?
Given a set of GPA data, SAT data and data on the percentile score on an aptitude test for a set of job applicants, to what extent can the GPA and SAT data explain the aptitude test score?
4.1.3 Walkthrough example
You are working as an analyst for the biology department of a large academic institution which offers a four-year undergraduate degree program. The academic leaders of the department are interested in understanding how student performance in the final-year examination of the degree program relates to performance in the prior three years.
To help with this, you have been provided with data for 975 individuals graduating in the past three years, and you have been asked to create a model to explain each individual’s final examination score based on their examination scores for the first three years of their program. The Year 1 examination scores are awarded on a scale of 0–100, Years 2 and 3 on a scale of 0–200, and the Final year is awarded on a scale of 0–300.
We will load the ugtests data set into our session and take a brief look at it.
# if needed, download ugtests data
url <- "http://peopleanalytics-regression-book.org/data/ugtests.csv"
ugtests <- read.csv(url)## Yr1 Yr2 Yr3 Final
## 1 27 50 52 93
## 2 70 104 126 207
## 3 27 36 148 175
## 4 26 75 115 125
## 5 46 77 75 114
## 6 86 122 119 159The data looks as expected, with test scores for four years all read in as numeric data types, but of course this is only a few rows. We need a quick statistical and structural overview of the data.
## 'data.frame': 975 obs. of 4 variables:
## $ Yr1 : int 27 70 27 26 46 86 40 60 49 80 ...
## $ Yr2 : int 50 104 36 75 77 122 100 92 98 127 ...
## $ Yr3 : int 52 126 148 115 75 119 125 78 119 67 ...
## $ Final: int 93 207 175 125 114 159 153 84 147 80 ...## Yr1 Yr2 Yr3 Final
## Min. : 3.00 Min. : 6.0 Min. : 8.0 Min. : 8
## 1st Qu.:42.00 1st Qu.: 73.0 1st Qu.: 81.0 1st Qu.:118
## Median :53.00 Median : 94.0 Median :105.0 Median :147
## Mean :52.15 Mean : 92.4 Mean :105.1 Mean :149
## 3rd Qu.:62.00 3rd Qu.:112.0 3rd Qu.:130.0 3rd Qu.:175
## Max. :99.00 Max. :188.0 Max. :198.0 Max. :295We can see that the results do seem to have different scales in the different years as we have been informed, and judging by the means, students seem to have found Year 2 exams more challenging. We can also be assured that there is no missing data, as these would have been displayed as NA counts in our summary if they existed.
We can also plot our four years of test scores pairwise to see any initial relationships of interest, as displayed in Figure 4.2.
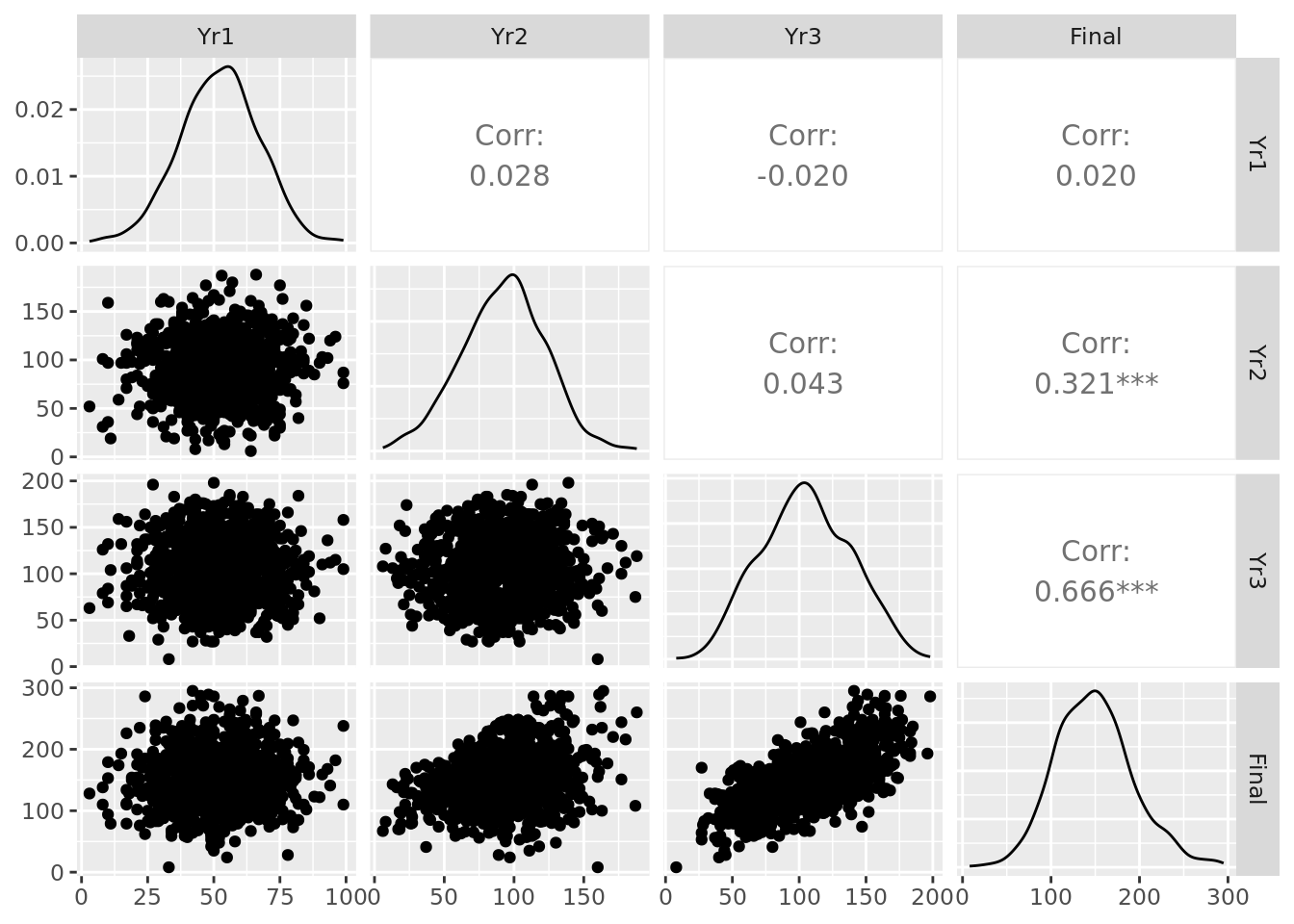
Figure 4.2: Pairplot of the ugtests data set
In the diagonal, we can see the distributions of the data in each column. We observe relatively normal-looking distributions in each year. We can see scatter plots and pairwise correlation statistics off the diagonal. For example, we see a particularly strong correlation between Yr3 and Final test scores, a moderate correlation between Yr2 and Final and relative independence elsewhere.
4.2 Simple linear regression
In order to visualize our approach and improve our intuition, we will start with simple linear regression, which is the case where there is only a single input variable and outcome variable.
4.2.1 Linear relationship between a single input and an outcome
Let our input variable be \(x\) and our outcome variable be \(y\). In Chapter 1, we introduced the concept of parametric modeling as an assumption that our outcome variable \(y\) is expected to be related to the input variable \(x\) by means of some mathematically definable function. In other words, we assume:
\[ y = f(x) + \epsilon \]
where \(f\) is some mathematical transformation of \(x\) and \(\epsilon\) is some random, uncontrollable error. Put another way, we assume that \(f(x)\) represents the mean expected value of \(y\) over many observations of \(x\), and that any single observation of \(y\) could vary from \(f(x)\) by an error of \(\epsilon\). Since we are assuming that \(f(x)\) represents the mean of \(y\), our errors \(\epsilon\) are therefore distributed around a mean of zero. We further assume that the distribution of our errors \(\epsilon\) is a normal distribution17.
Recalling the equation of a straight line, because we assume that the expected relationship is linear, it will take the form:
\[y = mx + c\] where \(m\) represents the slope or gradient of the line, and \(c\) represents the point at which the line intercepts the \(y\) axis. When using a straight line to model a relationship in the data, we call \(c\) and \(m\) the coefficients of the model.
Now let’s assume that we have a sample of 10 observations with which to estimate our linear relationship. Let’s take the first 10 values of Yr3 and Final in our ugtests data set:
## Yr3 Final
## 1 52 93
## 2 126 207
## 3 148 175
## 4 115 125
## 5 75 114
## 6 119 159
## 7 125 153
## 8 78 84
## 9 119 147
## 10 67 80We can do a simple plot of these observations as in Figure 4.3. Intuitively, we can imagine a line passing through these points that ‘fits’ the general pattern. For example, taking \(m = 1.2\) and \(c = 5\), the resulting line \(y = 1.2x + 5\) could fit between the points we are given, as displayed in Figure 4.4.
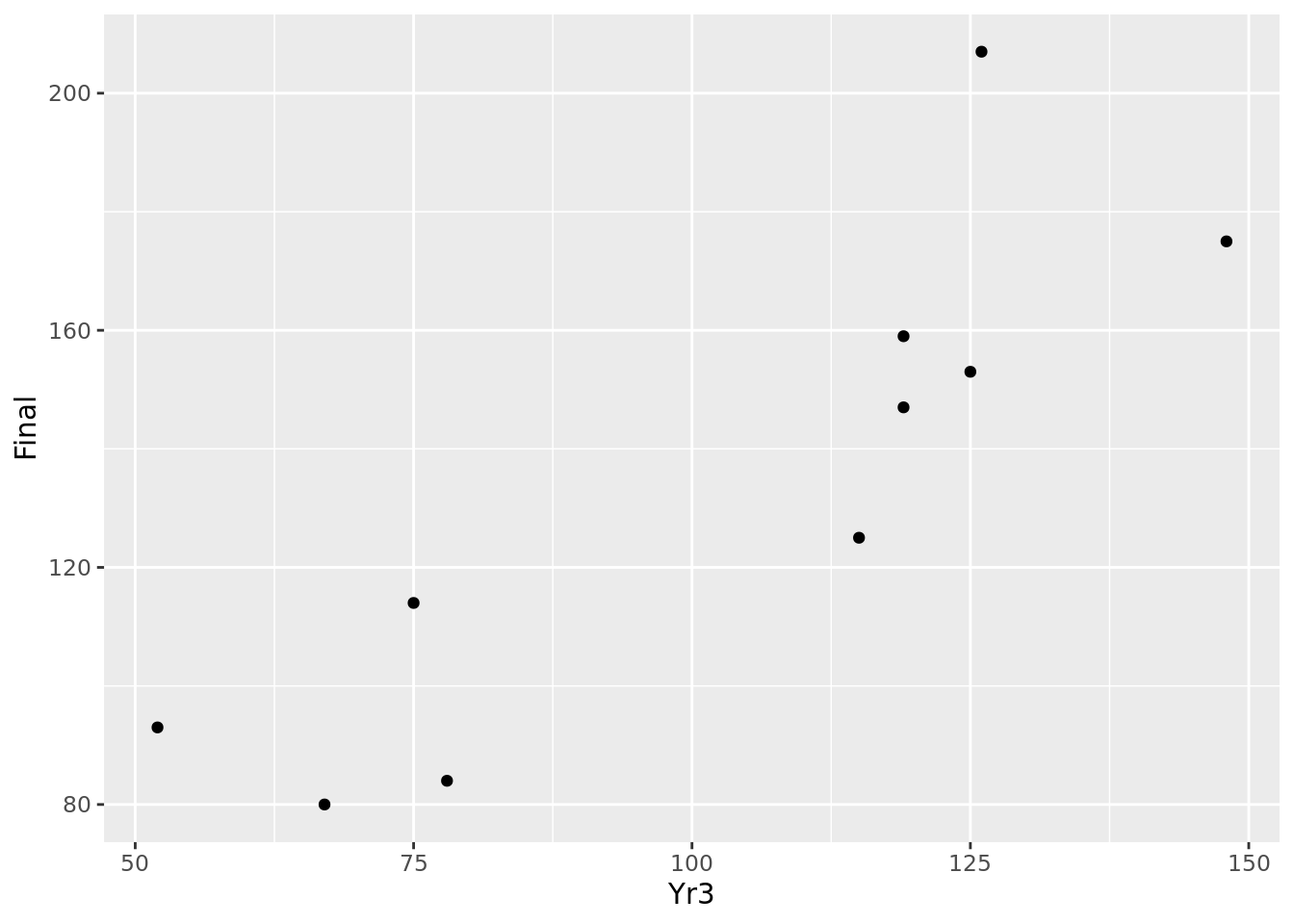
Figure 4.3: Basic scatter plot of 10 observations
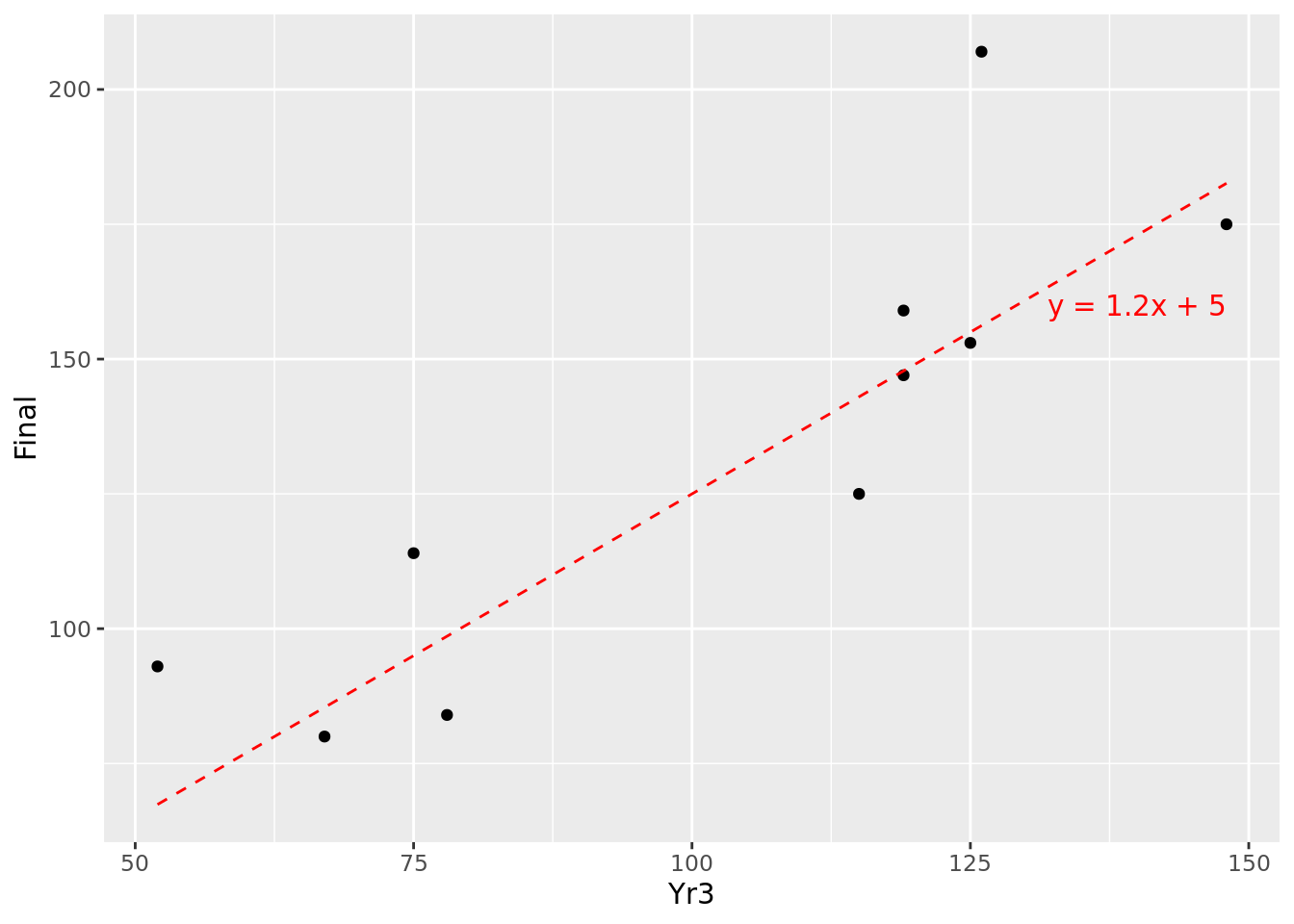
Figure 4.4: Fitting \(y=1.2x + 5\) to our 10 observations
This looks like an approximation of the relationship, but how do we know that it is the best approximation?
4.2.2 Minimising the error
Remember that our assumed relationship \(y = mx + c\) represents the expected mean value of \(y\) over many observations of \(x\). For a specific single observation of \(x\), we do not expect \(y\) to be precisely on our expected line, because each individual observation will have an error term \(\epsilon\) either above or below the expected line. We can determine this error term \(\epsilon\) in the fitted model by calculating the difference between the real value of \(y\) and the one predicted by our model. For example, at \(x = 52\), our modeled value of y is 67.4, but the real value is 93, producing an error \(\epsilon\) of 25.6. These errors \(\epsilon\) are known as the residuals of our model. The residuals for the 10 points in our data set are illustrated by the solid red line segments in Figure 4.5. It looks like at least one of our residuals is pretty large.
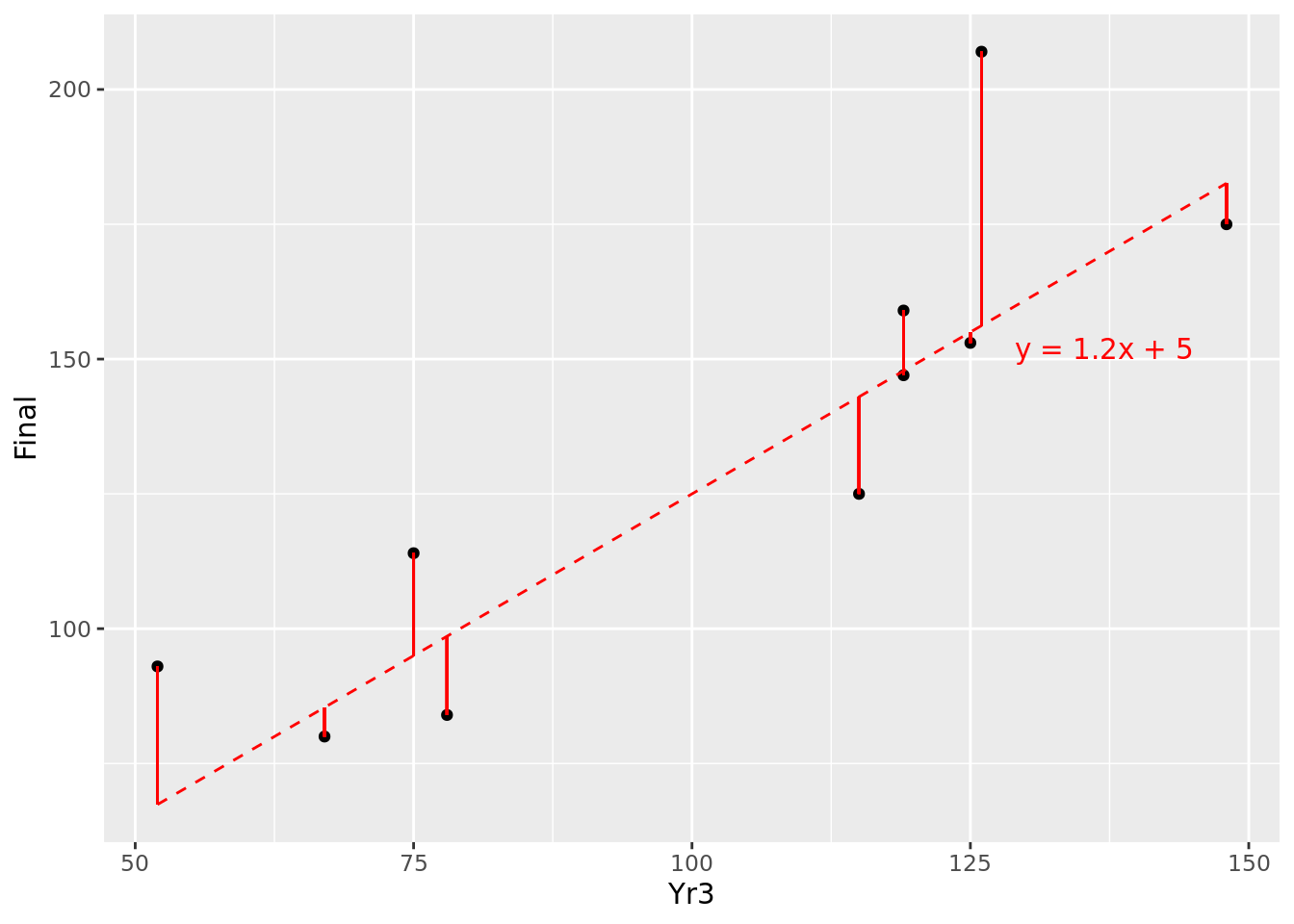
Figure 4.5: Residuals of \(y=1.2x + 5\) for our 10 observations
The error of our model—which we want to minimize—could be defined in a number of ways:
- The average of our residuals
- The average of the absolute values of our residuals (so that negative values are converted to positive values)
- The average of the squares of our residuals (note that all squares are positive)
For a number of reasons (not least the fact that at the time this method was developed it was one of the easiest to derive), the most common approach is number 3, which is why we call our regression model Ordinary Least Squares regression. Some algebra and calculus can help us determine the equation of the line that generates the least-squared residual error. For more of the theory behind this, consult Montgomery, Peck, and Vining (2012), but let’s look at how this works in practice.
4.2.3 Determining the best fit
We can run a fairly simple function in R to calculate the best fit linear model for our data. Once we have run that function, the model and all the details will be saved in our session for further investigation or use.
First we need to express the model we are looking to calculate as a formula. In this simple case, we want to regress the outcome \(y =\) Final against the input \(x =\) Yr3, and therefore we would use the simple formula notation Final ~ Yr3. Now we can use the lm() function to calculate the linear model based on our data set and our formula.
The model object that we have created is a list of a number of different pieces of information, which we can see by looking at the names of the objects in the list.
## [1] "coefficients" "residuals" "effects" "rank" "fitted.values" "assign" "qr"
## [8] "df.residual" "xlevels" "call" "terms" "model"So we can already see some terms we are familiar with. For example, we can look at the coefficients.
## (Intercept) Yr3
## 16.630452 1.143257This tells us that that our best fit model—the one that minimizes the average squares of the residuals—is \(y = 1.14x + 16.63\). In other words, our Final test score can be expected to take a value of 16.63 even with zero score in the Yr3 input, and every additional point scored in Yr3 will increase the Final score by 1.14.
4.2.4 Measuring the fit of the model
We have calculated a model which minimizes the average squared residual error for the sample of data that we have, but we don’t really have a sense of how ‘good’ the model is. How do we tell how well our model uses the input data to explain the outcome? This is an important question to answer because you would not want to propose a model that does not do a good job of explaining your outcome, and you also may need to compare your model to other alternatives, which will require some sort of benchmark metric.
One natural way to benchmark how good a job your model does of explaining the outcome is to compare it to a situation where you have no input and no model at all. In this situation, all you have is your outcome values, which can be considered a random variable with a mean and a variance. In the case of our 10 observations, we have 10 values of Final with a mean of 133.7. We can consider the horizontal line representing the mean of \(y\) as our ‘random model’, and we can calculate the residuals around the mean. This can be seen in Figure 4.6.
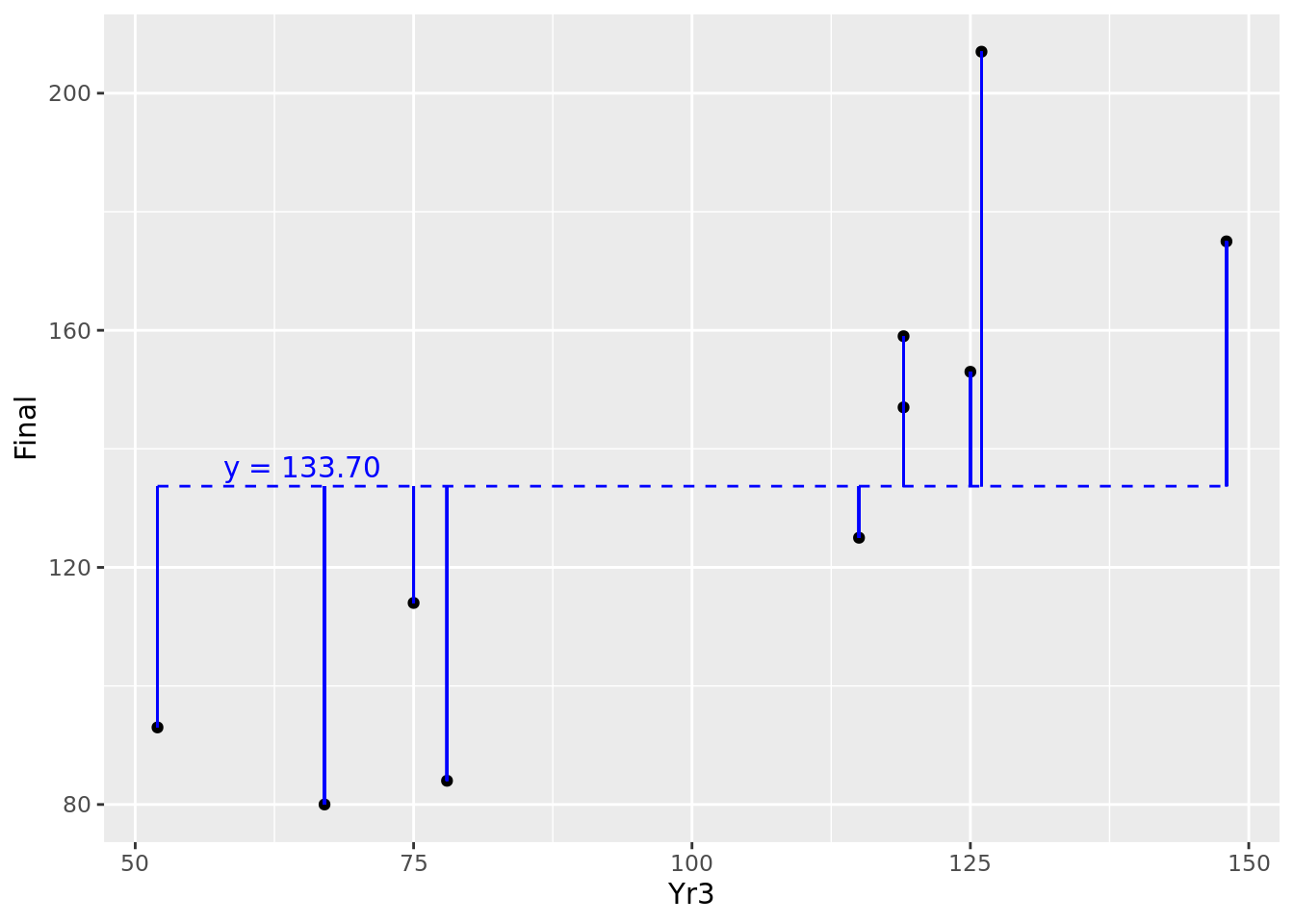
Figure 4.6: Residuals of our 10 observations around their mean value
Recall from Section 3.1.1 the definition of the population variance of \(y\), notated as \(\mathrm{Var}(y)\). Note that it is defined as the average of the squares of the residuals around the mean of \(y\). Therefore \(\mathrm{Var}(y)\) represents the average squared residual error of a random model. This calculates in this case to 1574.21. Let’s overlay our fitted model onto this random model in Figure 4.7.
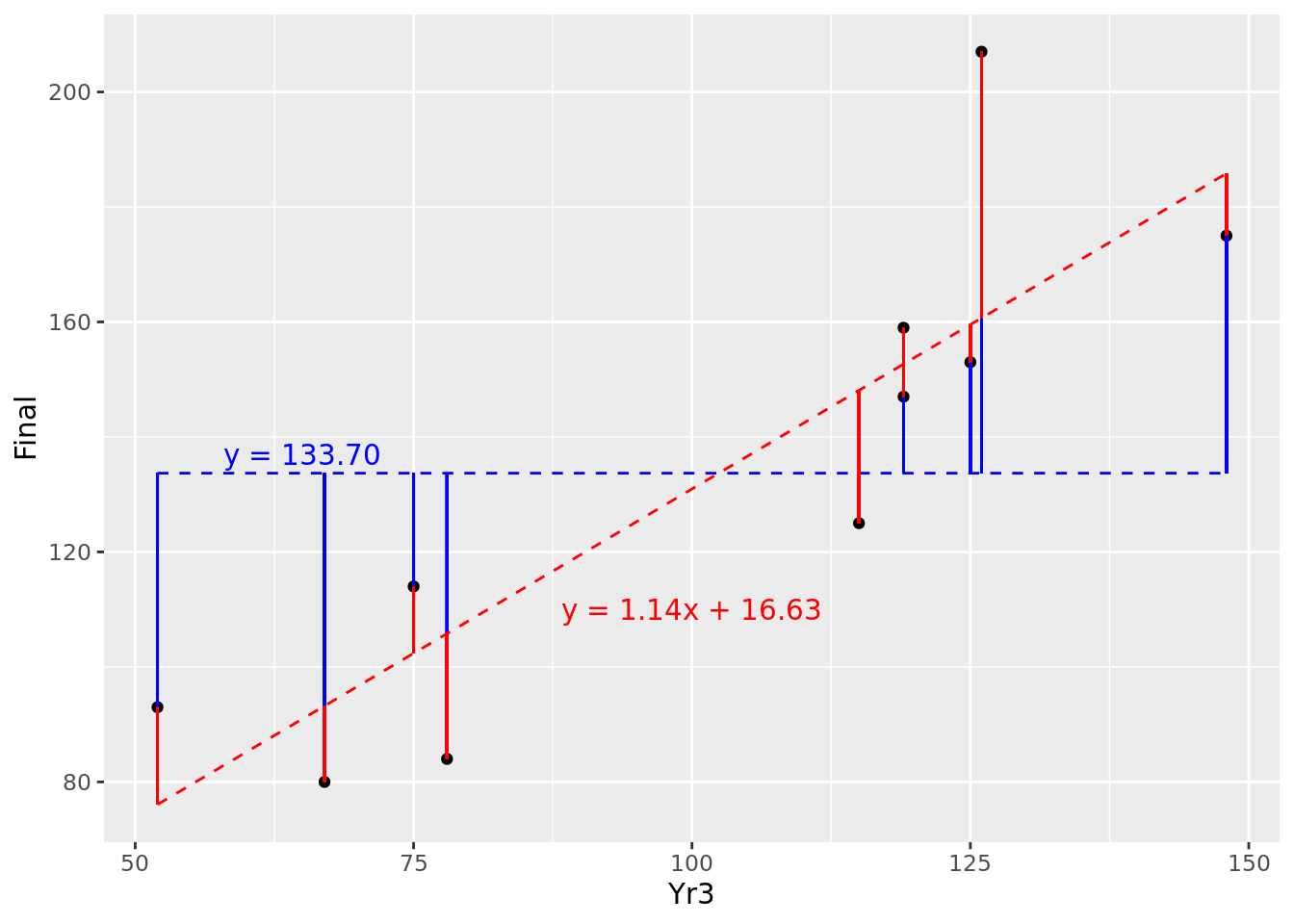
Figure 4.7: Comparison of residuals of fitted model (red) against random variable (blue)
So for most of our observations (though not all) we seem to have reduced the ‘distance’ from the random model by fitting our new model. If we average the square of our residuals for the fitted model, we obtain the average squared residual error of our fitted model, which calculates to 398.35.
Therefore, before we fit our model, we have an error of 1574.21, and after we fit it, we have an error of 398.35. So we have reduced the error of our model by 1175.86 or, expressed as a proportion, by 0.75. In other words, we can say that our model explains 0.75 (or 75%) of the variance of our outcome.
This metric is known as the \(R^2\) of our model and is the primary metric used in measuring the fit of a linear regression model18.
4.3 Multiple linear regression
In reality, regression problems rarely involve one single input variable, but rather multiple variables. The methodology for multiple linear regression is similar in nature to simple linear regression, but obviously more difficult to visualize because of its increased dimensionality.
In this case, our inputs are a set of \(p\) variables \(x_1, x_2, \dots, x_p\). Extending the linear equation in Section 4.2.1, we seek to develop an equation of the form:
\[y = \beta_0 + \beta_1x_1 + \beta_2x_2 + \dots + \beta_px_p\] so that our average squared residual error is minimized.
4.3.1 Running a multiple linear regression model and interpreting its coefficients
A multiple linear regression model is run in a similar way to a simple linear regression model, with your formula notation determining what outcome and input variables you wish to have in your model. Let’s now perform a multiple linear regression on our entire ugtests data set and regress our Final test score against all prior test scores using the formula Final ~ Yr3 + Yr2 + Yr1 and determine our coefficients as before.
## (Intercept) Yr3 Yr2 Yr1
## 14.14598945 0.86568123 0.43128539 0.07602621Referring to our formula in Section 4.3, let’s understand what each coefficient \(\beta_0, \beta_1, \dots, \beta_p\) means. \(\beta_0\), the intercept of the model, represents the value of \(y\) assuming that all the inputs were zero. You can imagine that your output can be expected to have a base value even without any inputs—a student who completely flunked the first three years can still redeem themselves to some extent in the Final year.
Now looking at the other coefficients, let’s consider what happens if our first input \(x_1\) increased by a single unit, assuming nothing else changed. We would then expect our value of y to increase by \(\beta_1\). Similarly for any input \(x_k\), a unit increase would result in an increase in \(y\) of \(\beta_k\), assuming no other changes in the inputs.
In the case of our ugtests data set, we can say the following:
The intercept of the model is 14.146. This is the value that a student could be expected to score on their final exam even if they had scored zero in all previous exams.
The
Yr3coefficient is 0.866. Assuming no change in other inputs, this is the increase in the Final exam score that could be expected from an extra point in the Year 3 score.The
Yr2coefficient is 0.431. Assuming no change in other inputs, this is the increase in the Final exam score that could be expected from an extra point in the Year 2 score.The
Yr1coefficient is 0.076. Assuming no change in other inputs, this is the increase in the Final exam score that could be expected from an extra point in the Year 1 score.
4.3.2 Coefficient confidence
Intuitively, these coefficients appear too precise for comfort. After all, we are attempting to estimate a relationship based on a limited set of data. In particular, looking at the Yr1 coefficient, it seems to be very close to zero, implying that there is a possibility that the Year 1 examination score has no impact on the final examination score. Like in any statistical estimation, the coefficients calculated for our model have a margin of error. Typically, in any such situation, we seek to know a 95% confidence interval to set a standard of certainty around the values we are interpreting.
The summary() function is a useful way to gather critical information in your model, including important statistics on your coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 14.14598945 5.48005618 2.581358 9.986880e-03
## Yr3 0.86568123 0.02913754 29.710169 1.703293e-138
## Yr2 0.43128539 0.03250783 13.267124 4.860109e-37
## Yr1 0.07602621 0.06538163 1.162807 2.451936e-01The 95% confidence interval corresponds to approximately two standard errors above or below the estimated value. For a given coefficient, if this confidence interval includes zero, you cannot reject the hypothesis that the variable has no relationship with the outcome. Another indicator of this is the Pr(>|t|) column of the coefficient summary, which represents the p-value of the null hypothesis that the input variable has no relationship with the outcome. If this value is less than a certain threshold (usually 0.05), you can conclude that this variable has a statistically significant relationship with the outcome. To see the precise confidence intervals for your model coefficients, you can use the confint() function.
## 2.5 % 97.5 %
## (Intercept) 3.39187185 24.9001071
## Yr3 0.80850142 0.9228610
## Yr2 0.36749170 0.4950791
## Yr1 -0.05227936 0.2043318In this case, we can conclude that the examinations in Years 2 and 3 have a significant relationship with the Final examination score, but we cannot conclude this for Year 1. Effectively, this means that we can drop Yr1 from our model with no substantial loss of fit. In general, simpler models are easier to manage and interpret, so let’s remove the non-significant variable now.
Given that our new model only has three dimensions, we have the luxury of visualizing it. Interactive Figure 4.8 shows the data and the fitted plane of our model.
Figure 4.8: 3D visualization of the fitted newmodel against the ugtests data
4.3.3 Model ‘goodness-of-fit’
At this point we can further explore the overall summary of our model. As you saw in the previous section, our model summary contains numerous objects of interest, including statistics on the coefficients of our model. We can see what is inside our summary by looking at the names of its contents, and we can then dive in and explore specific objects of interest.
# get summary of model
newmodel_summary <- summary(newmodel)
# see summary contents
names(newmodel_summary)## [1] "call" "terms" "residuals" "coefficients" "aliased" "sigma" "df"
## [8] "r.squared" "adj.r.squared" "fstatistic" "cov.unscaled"## [1] 0.5296734We can see that our model explains more than half of the variance in the Final examination score. Alternatively, we can view the entire summary to receive a formatted report on our model.
##
## Call:
## lm(formula = Final ~ Yr3 + Yr2, data = ugtests)
##
## Residuals:
## Min 1Q Median 3Q Max
## -91.12 -20.36 -0.22 18.94 98.29
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 18.08709 4.30701 4.199 2.92e-05 ***
## Yr3 0.86496 0.02914 29.687 < 2e-16 ***
## Yr2 0.43236 0.03250 13.303 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 30.44 on 972 degrees of freedom
## Multiple R-squared: 0.5297, Adjusted R-squared: 0.5287
## F-statistic: 547.3 on 2 and 972 DF, p-value: < 2.2e-16This provides us with some of the most important metrics from our model. In particular, the last line gives us a report on our overall model confidence or ‘goodness-of-fit’—this is a hypothesis test on the null hypothesis that our model does not fit the data any better than a random model. A high F-statistic indicates a strong likelihood that the model fits the data better than a random model. More intuitively, perhaps, we also have the p-value for the F-statistic. In this case it is extremely small, so we can reject the null hypothesis and conclude that our model has significant explanatory power over and above a random model.
Be careful not to confuse model goodness-of-fit with \(R^2\). Depending on your sample, it is entirely possible for a model with a low \(R^2\) to have high certainty for goodness-of-fit and vice versa.
4.3.4 Making predictions from your model
While this book focuses on inferential rather than predictive analytics, we briefly touch here on the mechanics of generating predictions from models. As you might imagine, once the model has been fitted, prediction is a relatively straightforward process. We feed the Yr2 and Yr3 examination scores into our fitted model, and it applies the coefficients to calculate the predicted outcome. Let’s look at three fictitious students and create a dataframe with their scores to input into the model.
## Yr2 Yr3
## 1 67 144
## 2 23 100
## 3 88 166Now we can feed these values into our model to get predictions of the Final examination result for our three new students.
## 1 2 3
## 171.6093 114.5273 199.7179Because we are modeling the expected value of the Final examination result, this prediction represents the expected mean over many students with the same scores in previous years examinations. We know from our earlier work in this chapter that there is a confidence interval around the coefficients of our model, which means that there is a range of values for our expected Final score according to those confidence intervals. This can be determined by specifying that you require a confidence interval for your predictions.
## fit lwr upr
## 1 171.6093 168.2125 175.0061
## 2 114.5273 109.7081 119.3464
## 3 199.7179 195.7255 203.7104As an example, another way of interpreting the confidence interval is to say that, if you have many students who scored precisely 67 and 144 in the Year 2 and Year 3 examinations respectively, we expect the mean Final score of these students to be somewhere between 168 and 175.
You may also recall from Section 4.2.1 that any prediction of an individual observation is subject to an error term \(\epsilon\). Therefore, to generate a more reliable prediction range for an individual observation, you should calculate a ‘prediction interval’.
## fit lwr upr
## 1 171.6093 111.77795 231.4406
## 2 114.5273 54.59835 174.4562
## 3 199.7179 139.84982 259.5860As discussed in Chapter 1, the process of developing a model to predict an outcome can be quite different from developing a model to explain an outcome. For a start, it is unlikely that you would use your entire sample to fit a predictive model, as you would want to reserve a portion of your data to test for its fit on new data. Since the focus of this book is inferential modeling, much of this topic will be out of our scope.
4.4 Managing inputs in linear regression
Our walkthrough example for this chapter, while useful for illustrating the key concepts, is a very straightforward data set to run a model on. There is no missing data, and all the data inputs have the same numeric data type (in the exercises at the end of this chapter we will present a more varied data set for analysis). Commonly, an analyst will have a list of possible input variables that they can consider in their model, and rarely will they run a model using all of these variables. In this section we will cover some common elements of decision making and design of input variables in regression models.
4.4.1 Relevance of input variables
The first step in managing your input variables is to make a judgment about their relevance to the outcome being modeled. Analysts should not blindly run a model on a set of variables before considering their relevance. There are two common reasons for rejecting the inclusion of an input variable:
There is no reasonable possibility of a direct or indirect causal relationship between the input and the outcome. For example, if you were provided with the height of each individual taking the Final examination in our walkthrough example, it would be difficult to see how that could reasonably relate to the outcome that you are modeling.
If there is a possibility that the model will be used to predict based on new data in the future, there may be variables that you explicitly do not wish to be used in any prediction. For example, if our walkthrough model contained student gender data, we would not want to include that in a model that predicted future student scores because we would not want gender to be taken into consideration when determining student performance.
4.4.2 Sparseness (‘missingness’) of data
Missing data is a very common problem in modeling. If an observation has missing data in a variable that is being included in the model, that observation will be ignored, or an error will be thrown. This forces a model trained on a smaller set of data, which can compromise its powers of inference. Running summary functions on your data (such as summary() in R) will reveal variables that contain missing data if they exist.
There are three main options for how missing data is handled:
If the data for a given variable is relatively complete and only a small number of observations are missing, it’s usually best and simplest to remove the observations that are missing from the data set. Note that many modeling functions (though not all) will take care of this automatically.
As data becomes more sparse, removing observations becomes less of an option. If the sparseness is massive (for example, more than half of the data is missing), then there is no choice but to remove that variable from the model. While this may be unsatisfactory for a given variable (because it is thought to have an important explanatory role), the fact remains that data that is mostly missing is not a good measure of a construct in the first place.
Moderate sparse data could be considered for imputation. Imputation methods involve using the overall statistical properties of the entire data set or of specific other variables to ‘suggest’ what the missing value might be, ranging from simple mean and median values to more complex imputation methods. Imputation methods are more commonly used in predictive settings, and we will not cover imputation methods in depth here.
4.4.3 Transforming categorical inputs to dummy variables
Many models will have categorical inputs rather than numerical inputs. Categorical inputs usually take forms such as:
- Binary values—for example, Yes/No, True/False
- Unordered categories—for example Car, Train, Bicycle
- Ordered categories—for example Low, Medium, High
Categorical variables do not behave like numerical variables. There is no sense of quantity in a categorical variable. We do not know how a Car relates to a Train quantitatively, we only know that they are different. Even for an ordered category, although we know that ‘Medium’ is higher than ‘Low’, we do not know how much higher or indeed whether the difference is the same as that between ‘High’ and ‘Medium’.
In general, all model input variables should take a numeric form. The most reliable way to do this is to convert categorical values to dummy variables. While some packages and functions have a built-in ability to convert categorical data to dummy variables, not all do, so it is important to know how to do this yourself. Consider the following data set:
(vehicle_data <- data.frame(
make = factor(c("Ford", "Toyota", "Audi")),
manufacturing_cost = c(15000, 19000, 28000)
))## make manufacturing_cost
## 1 Ford 15000
## 2 Toyota 19000
## 3 Audi 28000The make data is categorical, so it will be converted to several columns for each possible value of make, and binary labeling will be used to identify whether that value is present in that specific observation. Many packages and functions are available to conveniently do this, for example:
## make_Audi make_Ford make_Toyota manufacturing_cost
## 1 0 1 0 15000
## 2 0 0 1 19000
## 3 1 0 0 28000It is worth a moment to consider how to interpret coefficients of dummy variables in a linear regression model. Note that all observations will have one of the dummy variable values (all cars must have a make). Therefore the model will assume a ‘reference value’ for the categorical variable—often this is the first value in alphabetical or numerical order. In this case, Audi would be the reference dummy variable. The model then calculates the effect on the outcome variable of a ‘switch’ from Audi to one of the other dummies19. If we were to try to use the data in our vehicle_data_dummies data set to explain the retail price of a vehicle, we would interpret coefficients like this:
- Comparing two cars of the same make, we would expect each extra dollar spent on manufacturing to change the retail price by …
- Comparing a Ford with an Audi of the same manufacturing cost, we would expect a difference in retail price of …
- Comparing a Toyota with an Audi of the same manufacturing cost, we would expect a difference in retail price of …
This highlights the importance of appropriate interpretation of coefficients, and in particular the proper understanding of units. It will be common to see much larger coefficients for dummy variables in regression models because they represent a binary ‘all’ or ‘nothing’ variable in the model. The coefficient for manufacturing cost would be much smaller because a unit in this case is a dollar of manufacturing spend, on a scale of many thousands of potential dollars in spend. Care should be taken not to ‘rank’ coefficients by their value. Higher coefficients in and of themselves do not imply greater importance20.
4.5 Testing your model assumptions
All modeling techniques have underlying assumptions about the data that they model and can generate inaccurate results when those assumptions do not hold true. Conscientious analysts will verify that these assumptions are satisfied before finalizing their modeling efforts. In this section we will outline some common checks of model assumptions when running linear regression models.
4.5.1 Assumption of linearity and additivity
Linear regression assumes that the relationship we are trying to model is linear and additive in nature. Therefore you can expect problems if you are using this approach to model a pattern that is not linear or additive.
You can check whether your linearity assumption was reasonable in a couple of ways. You can plot the true versus the predicted (fitted) values to see if they look correlated. You can see such a plot on our student examination model in Figure 4.9.
predicted_values <- newmodel$fitted.values
true_values <- ugtests$Final
# plot true values against predicted values
plot(predicted_values, true_values)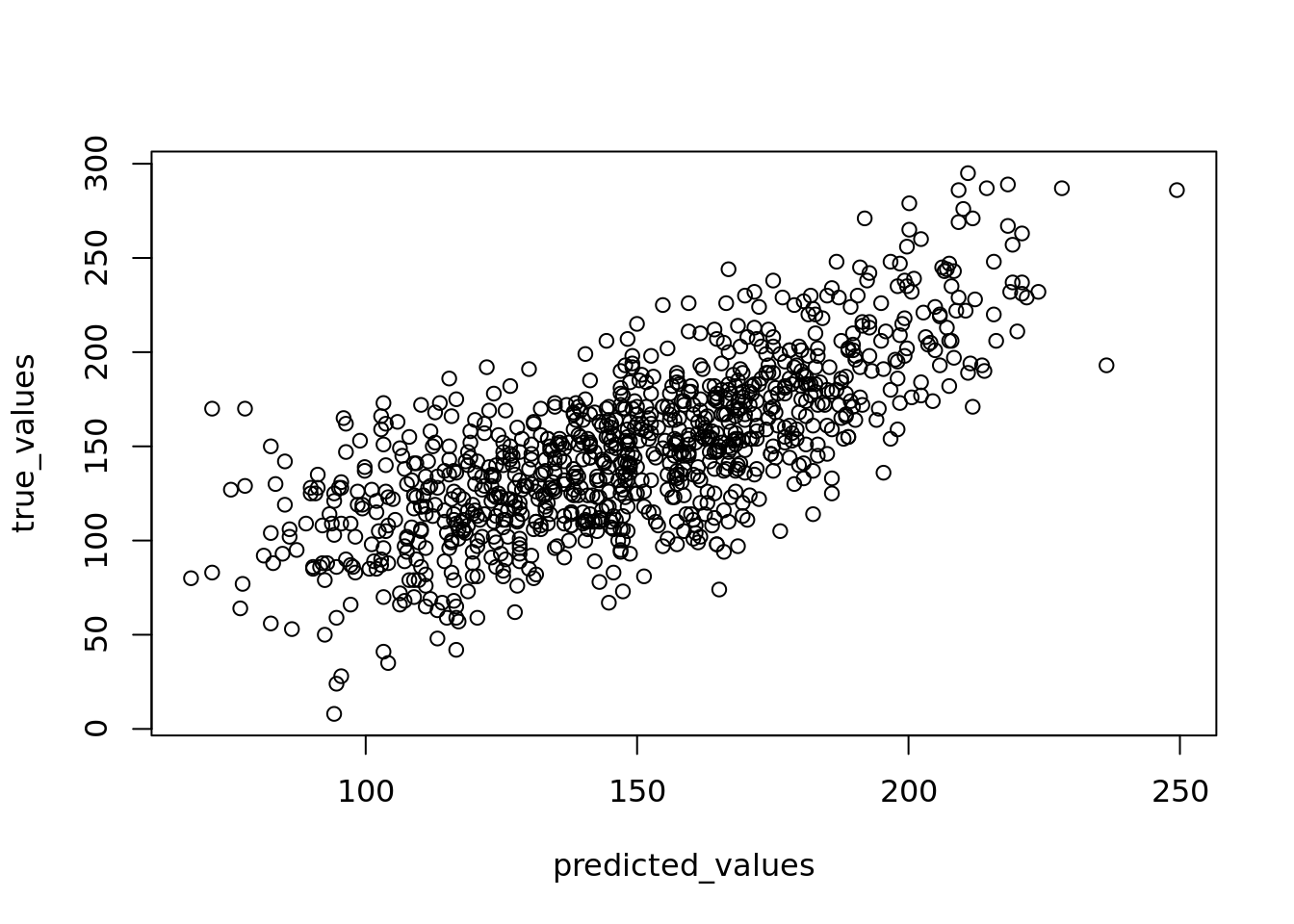
Figure 4.9: Plot of true versus fitted/predicted student scores
Alternatively, you can plot the residuals of your model against the predicted values and look for the pattern of a random distribution (that is, no major discernible pattern) such as in Figure 4.10.
residuals <- newmodel$residuals
# plot residuals against predicted values
plot(predicted_values, residuals)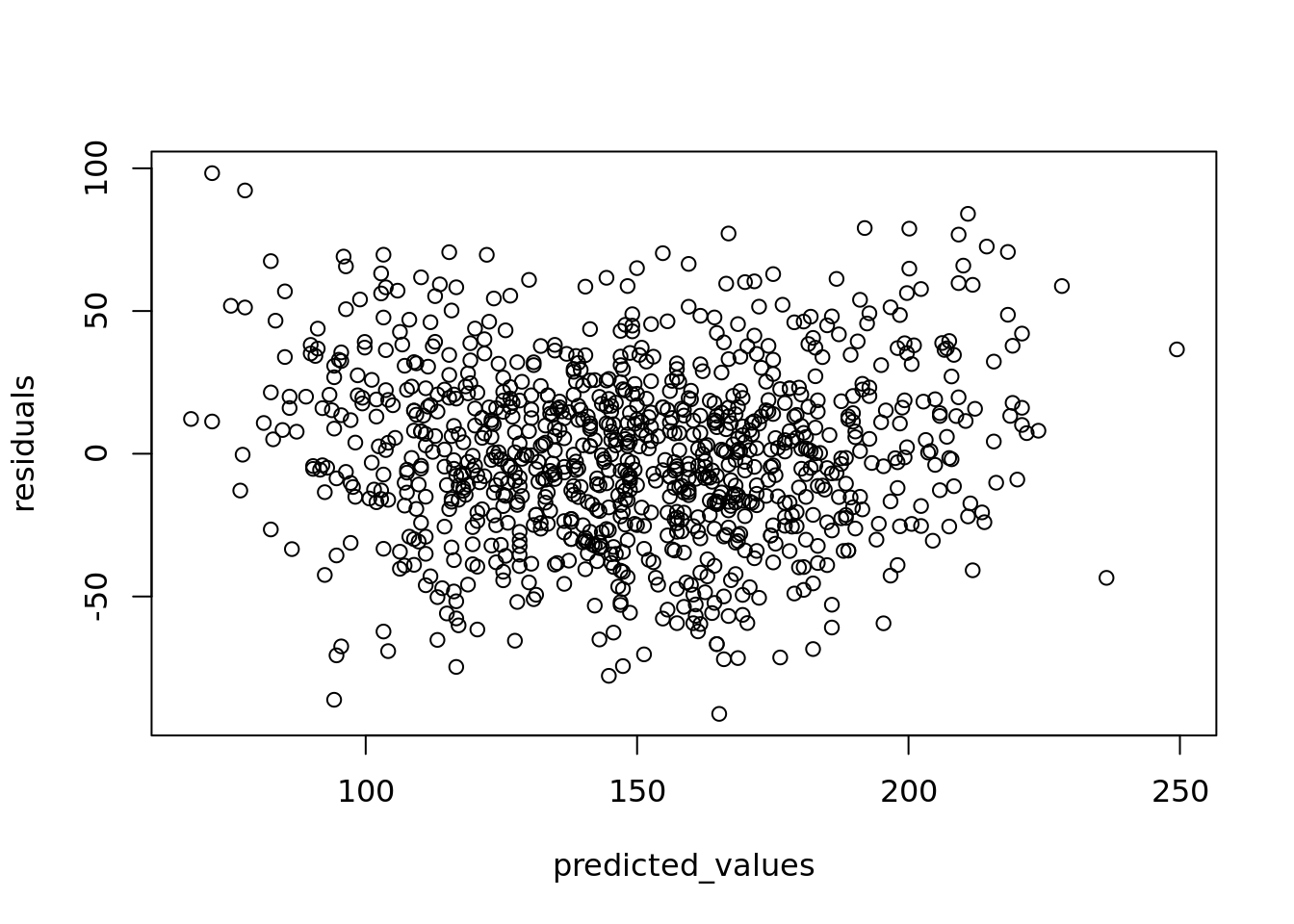
Figure 4.10: Plot of residuals against fitted/predicted scores
You can also plot the residuals against each input variable as an extra check of independent randomness, looking for a reasonably random distribution in all cases. If you find that your residuals are following a clear pattern and are not random in nature, this is an indication that a linear model is not a good choice for your data.
4.5.2 Assumption of constant error variance
It is assumed in a linear model that the errors or residuals are homoscedastic—this means that their variance is constant across the values of the input variables. If the errors of your model are heteroscedastic—that is, if they increase or decrease according to the value of the model inputs—this can lead to poor estimations and inaccurate inferences.
While a simple plot of residuals against predicted values (such as in Figure 4.10) can give a quick indication on homoscedacity, to be thorough the residuals should be plotted against each input variable, and it should be verified that the range of the residuals remains broadly stable. In our student examination model, we can first plot the residuals against the values of Yr2 in Figure 4.11.
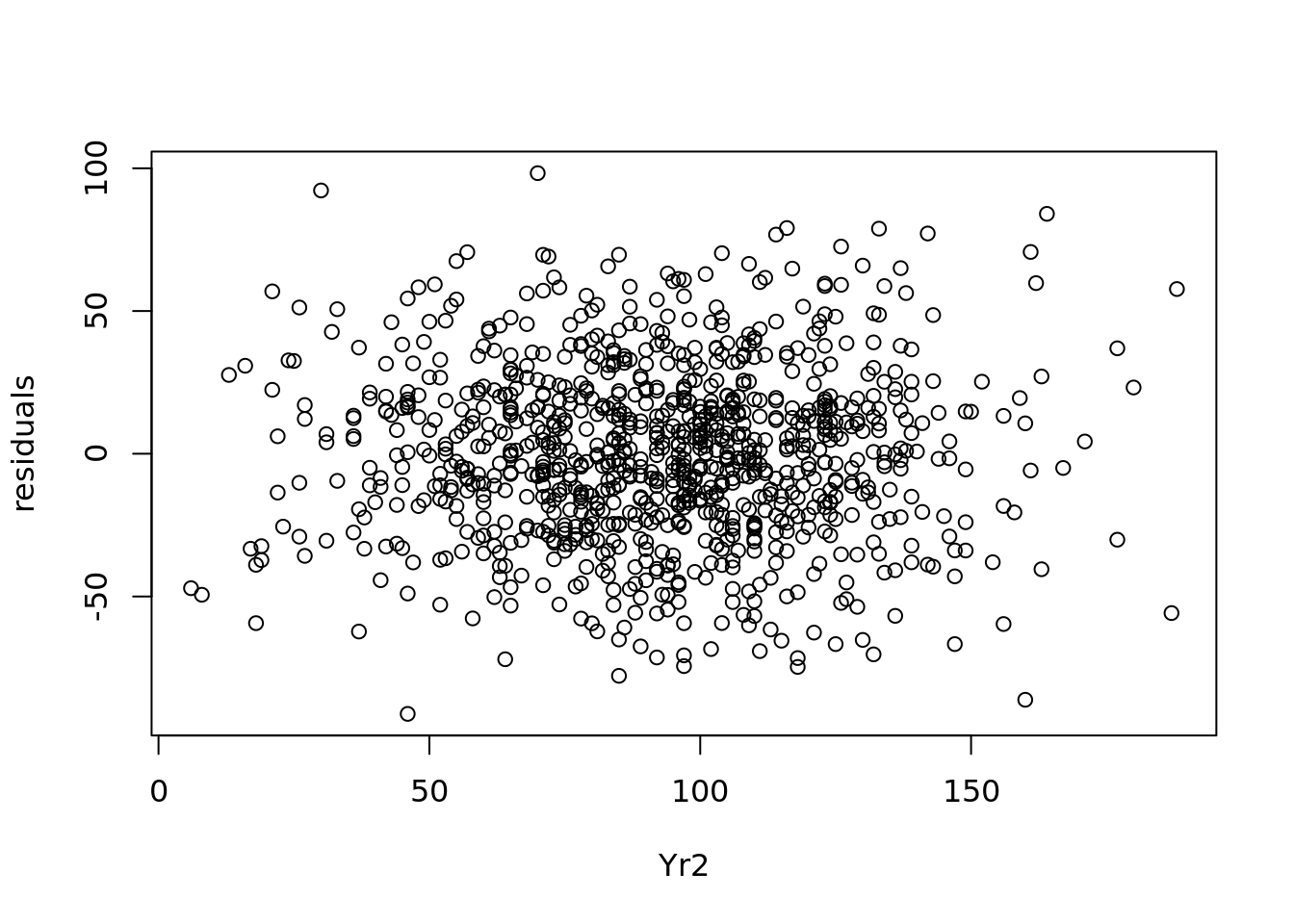
Figure 4.11: Plot of residuals against Yr2 values
We see a pretty consistent range of values for the residuals in 4.11. Similarly we can plot the residuals against the values of Yr3, as in Figure 4.12.
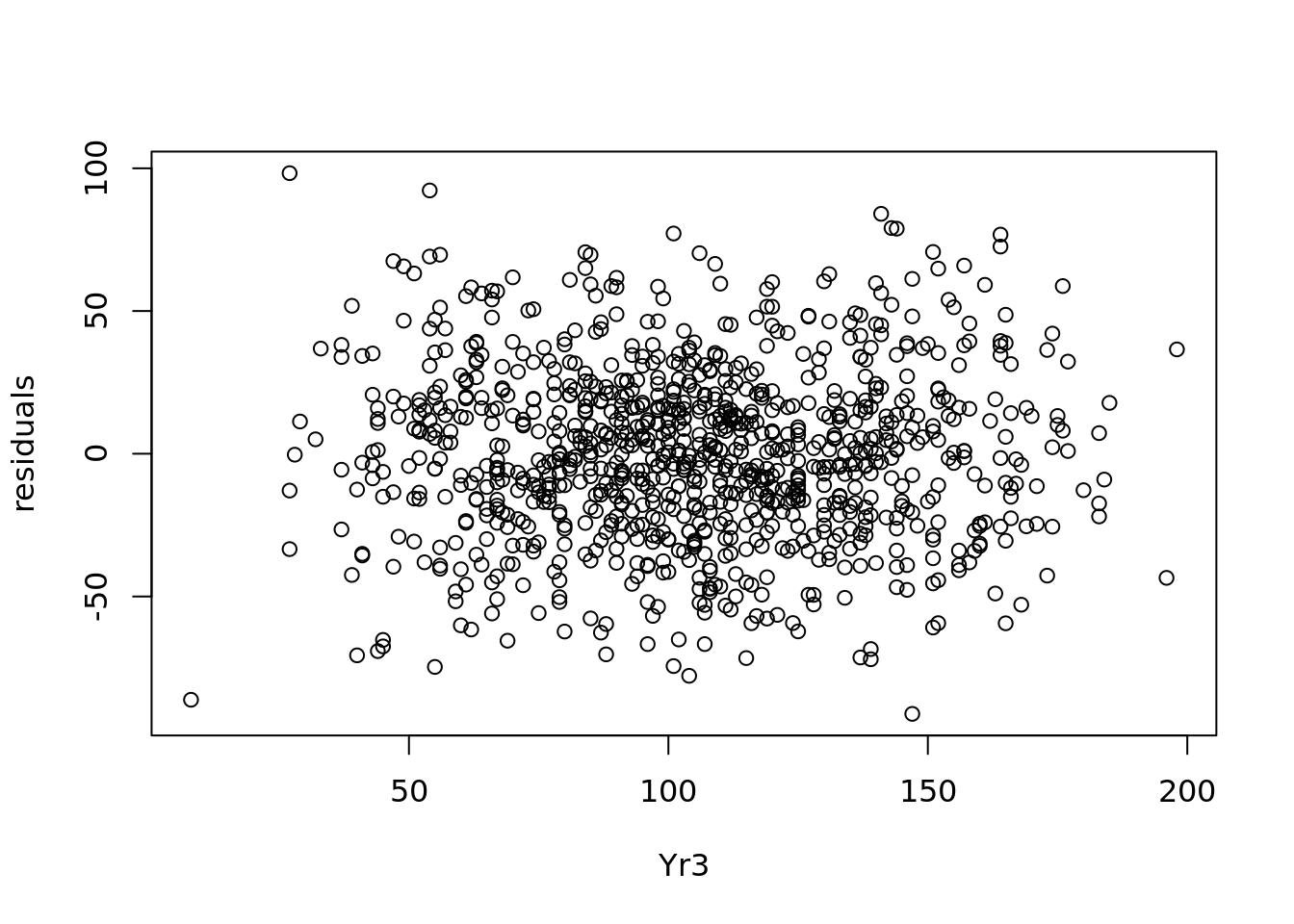
Figure 4.12: Plot of residuals against Yr3 values
Figure 4.12 also shows a consistent range of values for the residuals, which reassures us that we have homoscedacity.
4.5.3 Assumption of normally distributed errors
Recall from Section 4.2.1 that one of the assumptions when we run a linear regression model is that the residuals of the model are normally distributed around a mean of zero. Therefore it is useful to check your data to see how well it fits these assumptions. If your data shows that the residuals have a substantially non-normal distribution, this may tell you something about your model and how well you can rely on it for accurate inferences or predictions.
When residuals violate this assumption, it means that the ingoing mathematical premise of your model does not fully describe your data. Whether or not this is a big problem depends on the existing properties of your sample and on other model diagnostics. In models built on smaller samples, where hypothesis test criteria are only narrowly met, residual non-normality could present a significant challenge to the reliability of inferences and predictions. On models where hypothesis test criteria are very comfortably met, residual non-normality is less likely to be a problem (Lumley et al. (2002)). In any case, it is good practice to examine the distribution of your residuals so that you can refine or improve your model.
The quickest way to determine if residuals in your sample are consistent with a normal distribution is to run a quantile-quantile plot (or Q-Q plot) on the residuals. This will plot the observed quantiles of your sample against the theoretical quantiles of a normal distribution. The closer this plot looks like a perfect correlation, the more certain you can be that this normality assumption holds. An example for our student examination model is in Figure 4.13.
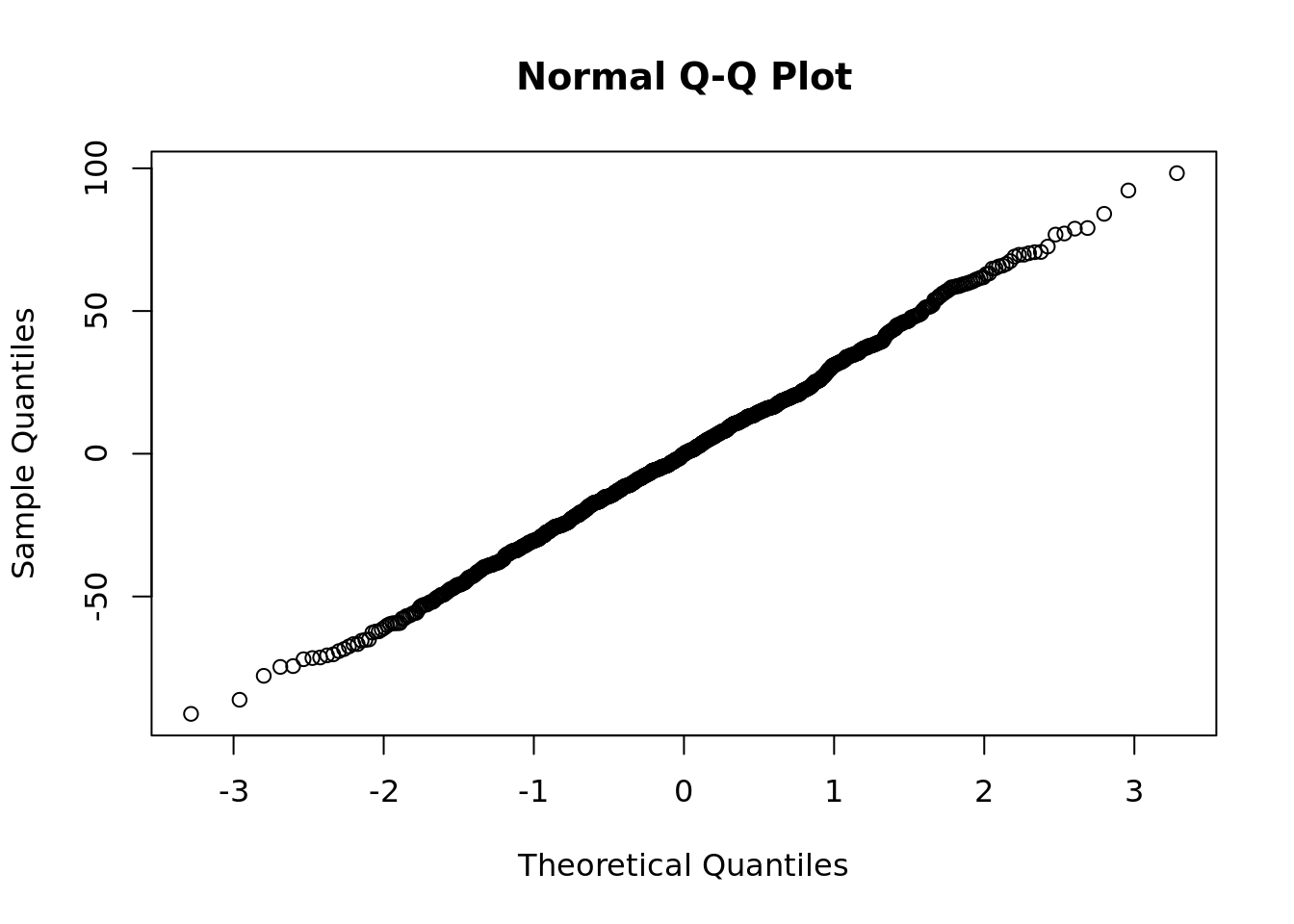
Figure 4.13: Quantile-quantile plot of residuals
4.5.4 Avoiding high collinearity and multicollinearity between input variables
In multiple linear regression, the various input variables used can be considered ‘dimensions’ of the problem or model. In theory, we ideally expect dimensions to be independent and uncorrelated. Practically speaking, however, it’s very challenging in large data sets to ensure that every input variable is completely uncorrelated from another. For example, even in our limited ugtests data set we saw in Figure 4.2 that Yr2 and Yr3 examination scores are correlated to some degree.
While some correlation between input variables can be expected and tolerated in linear regression models, high levels of correlation can result in significant inflation of coefficients and inaccurate estimates of p-values of coefficients.
Collinearity means that two input variables are highly correlated. The definition of ‘high correlation’ is a matter of judgment, but as a rule of thumb correlations greater than 0.5 might be considered high and greater than 0.7 might be considered extreme. Creating a simple correlation matrix or a pairplot (such as Figure 4.2) can immediately surface high or extreme collinearity.
Multicollinearity means that there is a linear relationship between more than two of the input variables. This may not always present itself in the form of high correlations between pairs of input variables, but may be seen by identifying ‘clusters’ of moderately correlated variables, or by calculating a Variance Inflation Factor (VIF) for each input variable—where VIFs greater than 5 indicate high multicollinearity. Easy-to-use tests also exist in statistical software for identifying multicollinearity (for example the mctest package in R). Here is how we would test for multicollinearity in our student examination model.
##
## Call:
## mctest::omcdiag(mod = newmodel)
##
##
## Overall Multicollinearity Diagnostics
##
## MC Results detection
## Determinant |X'X|: 0.9981 0
## Farrar Chi-Square: 1.8365 0
## Red Indicator: 0.0434 0
## Sum of Lambda Inverse: 2.0038 0
## Theil's Method: -0.5259 0
## Condition Number: 9.1952 0
##
## 1 --> COLLINEARITY is detected by the test
## 0 --> COLLINEARITY is not detected by the test# if necessary, diagnose specific multicollinear variables using VIF
mctest::imcdiag(newmodel, method = "VIF")##
## Call:
## mctest::imcdiag(mod = newmodel, method = "VIF")
##
##
## VIF Multicollinearity Diagnostics
##
## VIF detection
## Yr3 1.0019 0
## Yr2 1.0019 0
##
## NOTE: VIF Method Failed to detect multicollinearity
##
##
## 0 --> COLLINEARITY is not detected by the test
##
## ===================================Note that collinearity and multicollinearity only affect the coefficients of the variables impacted, and do not affect other variables or the overall statistics and fit of a model. Therefore, if a model is being developed primarily to make predictions and there is little interest in using the model to explain a phenomenon, there may not be any need to address this issue at all. However, in inferential modeling the accuracy of the coefficients is very important, and so testing of multicollinearity is essential. In general, the best way to deal with collinear variables is to remove one of them from the model (usually the one that has the least significance in explaining the outcome).
4.6 Extending multiple linear regression
We wrap up this chapter by introducing some simple extensions of linear regression, with a particular aim of trying to improve the overall fit of a model by relaxing the linear or additive assumptions. It is rare for practitioners to extend linear regression models too greatly due to the negative impact this can have on interpretation, but simple extensions such as experimenting with interaction terms or quadratics are not uncommon. If you have an appetite to explore this topic more fully, I recommend Rao et al. (2008).
4.6.1 Interactions between input variables
Recall that our model of student examination scores took each year’s score as an independent input variable, and therefore we are making the assumption that the score obtained in each year acts independently and additively in predicting the Final score. However, it is very possible that several input variables act together in relation to the outcome. One way of modeling this is to include interaction terms in your model, which are new input variables formed as products of the original input variables.
In our student examination data in ugtests, we could consider extending our model to not only include the individual year examinations, but also to include the impact of combined changes across multiple years. For example, we could combine the impact of Yr2 and Yr3 examinations by multiplying them together in our model.
interaction_model <- lm(data = ugtests,
formula = Final ~ Yr2 + Yr3 + Yr2*Yr3)
summary(interaction_model)##
## Call:
## lm(formula = Final ~ Yr2 + Yr3 + Yr2 * Yr3, data = ugtests)
##
## Residuals:
## Min 1Q Median 3Q Max
## -78.084 -18.284 -0.546 18.395 79.824
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 1.320e+02 1.021e+01 12.928 < 2e-16 ***
## Yr2 -7.947e-01 1.056e-01 -7.528 1.18e-13 ***
## Yr3 -2.267e-01 9.397e-02 -2.412 0.0161 *
## Yr2:Yr3 1.171e-02 9.651e-04 12.134 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 28.38 on 971 degrees of freedom
## Multiple R-squared: 0.5916, Adjusted R-squared: 0.5903
## F-statistic: 468.9 on 3 and 971 DF, p-value: < 2.2e-16We see that introducing this interaction term has improved the fit of our model from 0.53 to 0.59, and that the interaction term is significant, so we conclude that in addition to a significant effect of the Yr2 and Yr3 scores, there is an additional significant effect from their interaction Yr2*Yr3. Let’s take a moment to understand how to interpret this, since we note that some of the coefficients are now negative.
Our model now includes two input variables and their interaction, so it can be written as
\[ \begin{aligned} \mathrm{Final} &= \beta_0 + \beta_1\mathrm{Yr3} + \beta_2\mathrm{Yr2} + \beta_3\mathrm{Yr3}\mathrm{Yr2} \\ &= \beta_0 + (\beta_1 + \beta_3\mathrm{Yr2})\mathrm{Yr3} + \beta_2\mathrm{Yr2} \\ &= \beta_0 + \gamma\mathrm{Yr3} + \beta_2\mathrm{Yr2} \end{aligned} \] where \(\gamma = \beta_1 + \beta_3\mathrm{Yr2}\). Therefore our model has coefficients which are not constant but change with the values of the input variables. We can conclude that the effect of an extra point in the examination in Year 3 will be different depending on how the student performed in Year 2. Visualizing this, we can see in Interactive Figure 4.14 that this non-constant term introduces a curvature to our fitted surface that aligns it a little more closely with the observations in our data set.
Figure 4.14: 3D visualization of the fitted interaction_model against the ugtests data
By examining the shape of this curved plane, we can observe that the model considers trajectories in the Year 2 and Year 3 examination scores. Those individuals who have improved from one year to the next will perform better in this model than those who declined. To demonstrate, let’s look at the predicted scores from our interaction_model for someone who declined and for someone who improved from Year 2 to Year 3.
# data frame with a declining and an improving observation
obs <- data.frame(
Yr2 = c(150, 75),
Yr3 = c(75, 150)
)
predict(interaction_model, obs)## 1 2
## 127.5010 170.1047Through including the interaction effect, the model interprets declining examination scores more negatively than improving examination scores. These kinds of additional inferential insights may be of great interest. However, consider the impact on interpretability of modeling too many combinations of interactions. As always, there is a trade-off between intepretability and accuracy21.
When running models with interaction terms, you can expect to see a hierarchy in the coefficients according to the level of the interaction. For example, single terms will usually generate higher coefficients than interactions of two terms, which will generate higher coefficients than interactions of three terms, and so on. Given this, whenever an interaction of terms is considered significant in a model, then the single terms contained in that interaction should automatically be regarded as significant.
4.6.2 Quadratic and higher-order polynomial terms
In many situations the real underlying relationship between the outcome and the inputs may be non-linear. For example, if the underlying relationship was thought to be quadratic on a given input variable \(x\), then the formula would take the form \(y = \beta_0 + \beta_1x + \beta_2x^2\). We can easily trial polynomial terms using our linear model technology.
For example, recall that we removed Yr1 data from our model because it was not significant when modeled linearly. We could test if a quadratic model on Yr1 helps improve our fit22:
# add a quadratic term in Yr1
quadratic_yr1_model <- lm(data = ugtests,
formula = Final ~ Yr3 + Yr2 + Yr1 + I(Yr1^2))
# test R-squared
summary(quadratic_yr1_model)$r.squared## [1] 0.5304198In this case we find that modeling Yr1 as a quadratic makes no difference to the fit of the model.
4.7 Learning exercises
4.7.1 Discussion questions
What is the approximate meaning of the term ‘regression’? Why is the term particularly suited to the methodology described in this chapter?
What basic condition must the outcome variable satisfy for linear regression to be a potential modeling approach? Describe some ideas for problems that might be modeled using linear regression.
What is the difference between simple linear regression and multiple linear regression?
What is a residual, and how does it relate to the term ‘Ordinary Least Squares’?
How are the coefficients of a linear regression model interpreted? Explain why higher coefficients do not necessarily imply greater importance.
How is the \(R^2\) of a linear regression model interpreted? What are the minimum and maximum possible values for \(R^2\), and what does each mean?
What are the key considerations when preparing input data for a linear regression model?
Describe your understanding of the term ‘dummy variable’. Why are dummy variable coefficients often larger than other coefficients in linear regression models?
Describe the term ‘collinearity’ and why it is an important consideration in regression models.
Describe some ways that linear regression models can be extended into non-linear models.
4.7.2 Data exercises
Load the sociological_data data set via the peopleanalyticsdata package or download it from the internet23. This data represents a sample of information obtained from individuals who participated in a global research study and contains the following fields:
annual_income_ppp: The annual income of the individual in PPP adjusted US dollarsaverage_wk_hrs: The average number of hours per week worked by the individualeducation_months: The total number of months spent by the individual in formal primary, secondary and tertiary educationregion: The region of the world where the individual livesjob_type: Whether the individual works in a skilled or unskilled professiongender: The gender of the individualfamily_size: The size of the individual’s family of dependentswork_distance: The distance between the individual’s residence and workplace in kilometerslanguages: The number of languages spoken fluently by the individual
Conduct some exploratory data analysis on this data set. Including:
- Identify the extent to which missing data is an issue.
- Determine if the data types are appropriate for analysis.
- Using a correlation matrix, pairplot or alternative method, identify whether collinearity is present in the data.
- Identify and discuss anything else interesting that you see in the data.
Prepare to build a linear regression model to explain the variation in annual_income_ppp using the other data in the data set.
- Are there any fields which you believe should not be included in the model? If so, why?
- Would you consider imputing missing data for some or all fields where it is an issue? If so, what might be some simple ways to impute the missing data?
- Which variables are categorical? Convert these variables to dummy variables using a convenient function or using your own approach.
Run and interpret the model. For convenience, and to avoid long formula strings, you can use the formula notation annual_income_ppp ~ . which means ‘regress annual_income against everything else’. You can also remove fields this way, for example annual_income_ppp ~ . - family_size.
- Determine what variables are significant predictors of annual income and what is the effect of each on the outcome.
- Determine the overall fit of the model.
- Do some simple analysis on the residuals of the model to determine if the model is safe to interpret.
- Experiment with improving the model fit through possible interaction terms or non-linear extensions.
- Comment on your results. Did anything in the results surprise you? If so, what might be possible explanations for this.
- Explain why you would or would not be comfortable using a model like this in a predictive setting—for example to help employers determine the right pay for employees.
References
This chart includes a random ‘jitter’ to better illustrate observations that are identical and was first used to illustrate Galton’s data in Senn (2011).↩︎
This assumption is necessary in order for the estimations of the model parameters to be determined.↩︎
As a side note, in a simple regression model like this, where there is only one input variable, we have the simple identity \(R^2 = r^2\), where \(r\) is the correlation between the input and outcome (for our small set of 10 observations here, the correlation is 0.864).↩︎
For more on how to control which categorical value is used as a reference, see Section 6.3.1.↩︎
Rescaling numerical input variables onto common scales can help with understanding the ranked importance of these variables. In some techniques, for example structural modeling which we will review in Section 8.2, scaled regression coefficients help determine the ranked importance of constructs to the outcome.↩︎
In a predictive context, there is also the issue of ‘overfitting’ the model, where the model is too ‘tightly’ aligned to the past data that was used in fitting it that it may be very inaccurate for new data. For example, in our interaction model, someone who scores very low in both Year 2 and Year 3 will be awarded an unreasonably high score (see the intercept coefficient in the interactive model summary). This reinforces the need to test and validate model fits in a predictive context.↩︎
Note the use of
I()in the formula notation here. This is because the symbol^has a different meaning inside a formula, and we useI()to isolate what is inside the parentheses to ensure that it is interpreted literally as ‘the square ofYr1’.↩︎http://peopleanalytics-regression-book.org/data/sociological_data.csv↩︎